
A Beginner’s Guide To The Single Table Design In DynamoDB
The what, why and how of implementing the single table design with DynamoDB.


If you’ve ever heard of the single table design, you know it’s a game-changer for NoSQL database design.
If you have been using DynamoDB with multiple tables, you know you’ve been doing it wrong.
It’s probably what brought you here.
So let’s get right into it.
What is the single table design?
When coming from SQL it makes sense to use one table per entity.
If you have an e-commerce website, you typically have a table for each data type:
customers
sellers
orders
transactions
products
Then with foreign keys you can join and query related data together.
The issue is with NoSQL databases, like DynamoDB, there are no joins.
You cannot use foreign keys to join related data together.
So how then can you fetch related data with DynamoDB?
The answer is of course: the single table design.
Since you cannot join tables, there is little use in creating multiple tables.
The single table design is an NoSQL data modeling strategy where you store all your data on one table with the intention to query related items together.
Let’s look at a basic example of this single table design.

First, notice that in this table we are storing the following items together:
users
orders
transactions
payments
shipments
The second thing to pay attention to is the naming of our primary keys “pk” and “sk”.
Rather than using specific attribute key names like “userID” or “productID”, we use arbitrary names “pk” and “sk”.
We do this because now that we have multiple entities in our table, “userID” cannot accurate define an item’s key since we don’t only have user items.
Why use the single table design?
Now you might be wondering, why should we be using one table? Won’t the table become confusing with a mix of different data?
Yes it will. But we are making a tradeoff on a visually hard to read database — which is actually not important — in exchange for more efficient and faster data fetching.
Here’s why:
With this table design, we store related data in the same partition. Notice how the different items (user, orders, transactions, shipments) are all stored under the “user-101” partition.
Since all these items “belong” to a specific user, we can store them with that user. Then when we need to fetch that user’s info, orders and transactions we can make a single query to our table.
Here’s the key: if we stored each data type on its own table, we’d need to make three separate queries for each item:
The first query to get the user’s data.
A second query to get the user’s orders.
A third query to get the user’s transactions on these orders
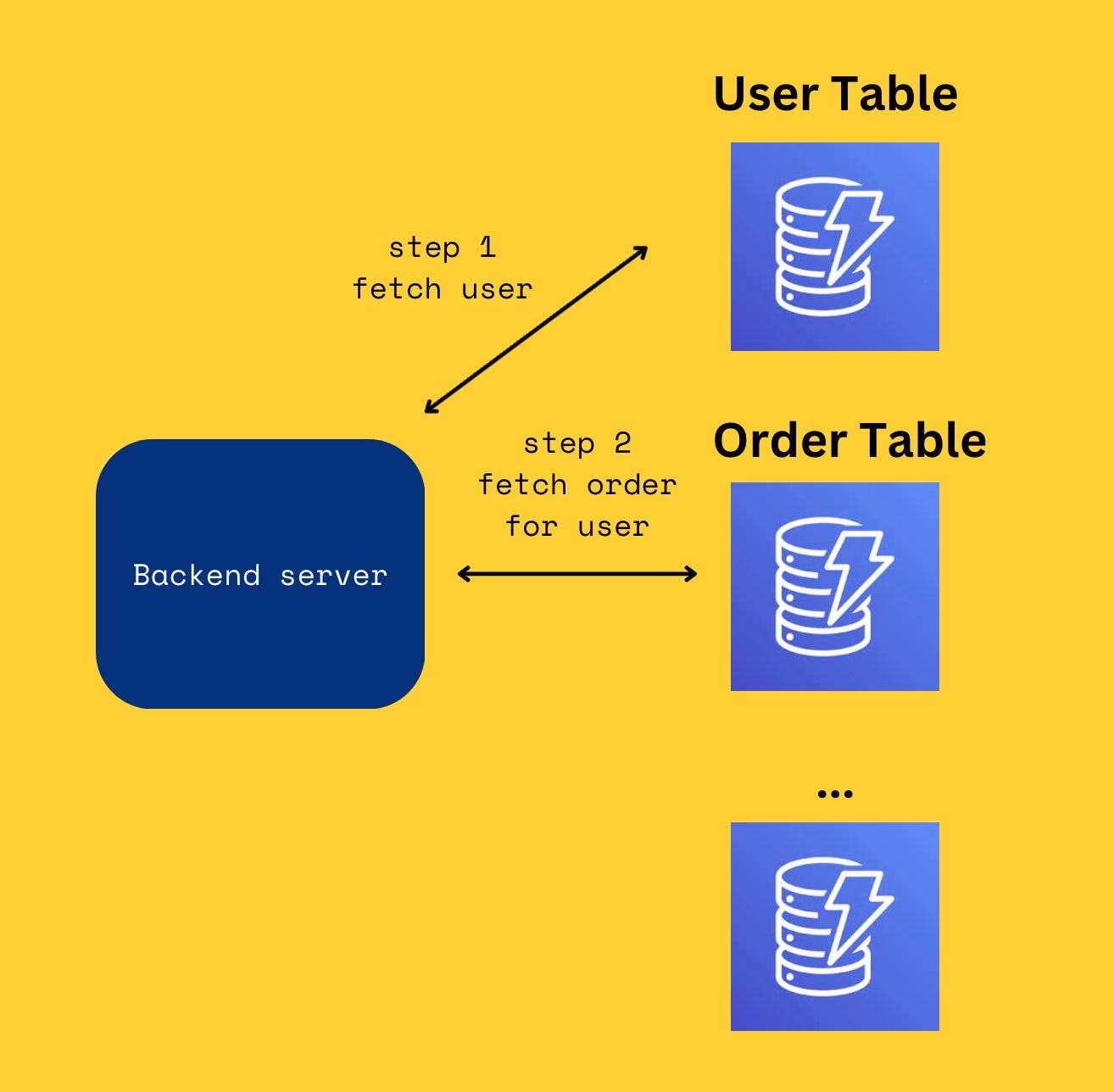

That’s three queries that need to be run in sequence. This is because the user’s orders depend on the user’s userID and the transactions depend on the orders items.
Running these three queries would take a longer time and costs three times as much.
However, with the single table design, we need only a single query for the data in the user’s partition.
On a side note, DynamoDB charges you on the provisioned capacity you set per table. This means each table you create costs you x times more money than using one table for all your data.
How to use the single table design

There are three concepts you need to understand to build a basic single table effectively:
1. Use arbitrary primary keys
As mentioned earlier, use “pk” for your partition key and “sk” for your sort key to define all items.
For global secondary indexes (GSIs), use “gsi1pk” and “gsi1sk”, and increment that number for each additional GSI keys you need.
This is also where key overloading comes into play. You can use key overloading to satisfy multiple access patterns.
Key overloading is a technique where you use multiple values within your partition or sort key.
An example of this would be:
pk: "canada",
sk: "ontario#toronto#m4xoa1"In this sort key, I can store multiple values so that I can filter items by location.
2. Data that you fetch together should be stored together
The single table design image above shows that the user-101’s data is stored under their partition to enable efficient queries using only their partition key.
I can use the following query to store all of this data together:
KeyConditionExpression: "pk = :pk",
ExpressionAttributeValues: {
":pk": `user-101`
}However, if my application only requires to fetch user orders and transactions together then I can create a partition like “user-101-orders” and only store order and transaction items there.
3. Understand the begins_with() method
When using the single table design, it is crucial to understand the begins_with() method.
When you model your data for one table, it’s recommended to prefix the sort key (and optionally the partition key) with the entity type followed by a hash.
Here’s an example:
pk: "user#101",
sk: "order#201"This is done so that when a user has multiple order items, they can fetch all the orders using the begins_with() method:
KeyConditionExpression: "pk = :pk AND begins_with(sk, :sk)",
ExpressionAttributeValues: {
":pk": "user#101",
":sk": "order#,
},In simple terms, the above query says:
Get me all items where the “pk” value equals to “user#101” and the “sk” value begins with the string “order#”.
No matter what orderID an order has, it will fall into this query since all orders are prefixed with “order#”.
DynamoDB has more methods like BETWEEN, equality operators and much more to perform powerful queries.
You can check them out here.
If you want to get into more advanced concepts of the single table design, I wrote this article on modeling the data for a social network using the single table design.
Conclusion
The single table design allows you to model your data for maximum efficiency and data retrieval speeds. It helps you reduce costs and improves performance by grouping and fetching related data together.
By mastering techniques like data modeling for a single table and understanding the begins_with() method you can build scalable and efficient databases with DynamoDB.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!