
Designing a Serverless Event-Driven Workflow for Image Uploads at Scale
How I would design this with serverless AWS services

I recently designed and built a serverless image uploading microservice for a legal software this month.
The flow went like this: a user submits an image (either as a standalone upload or inside a chat conversation. The system must compress, resize, and store that image to the database quickly and securely.
The architecture was simple and straightforward for a soft MVP launch.
However, eventually this system will come to a point where it will be used by several thousand monthly active users. It is at this point where I will have to redesign the system for scalability.
In this article, I’ll guide you through my strategy of this preemptive architectural design that will support thousands of image upload requests per second. I’ll also break down each component and explaining how it fits into the bigger picture.
Architectural Overview
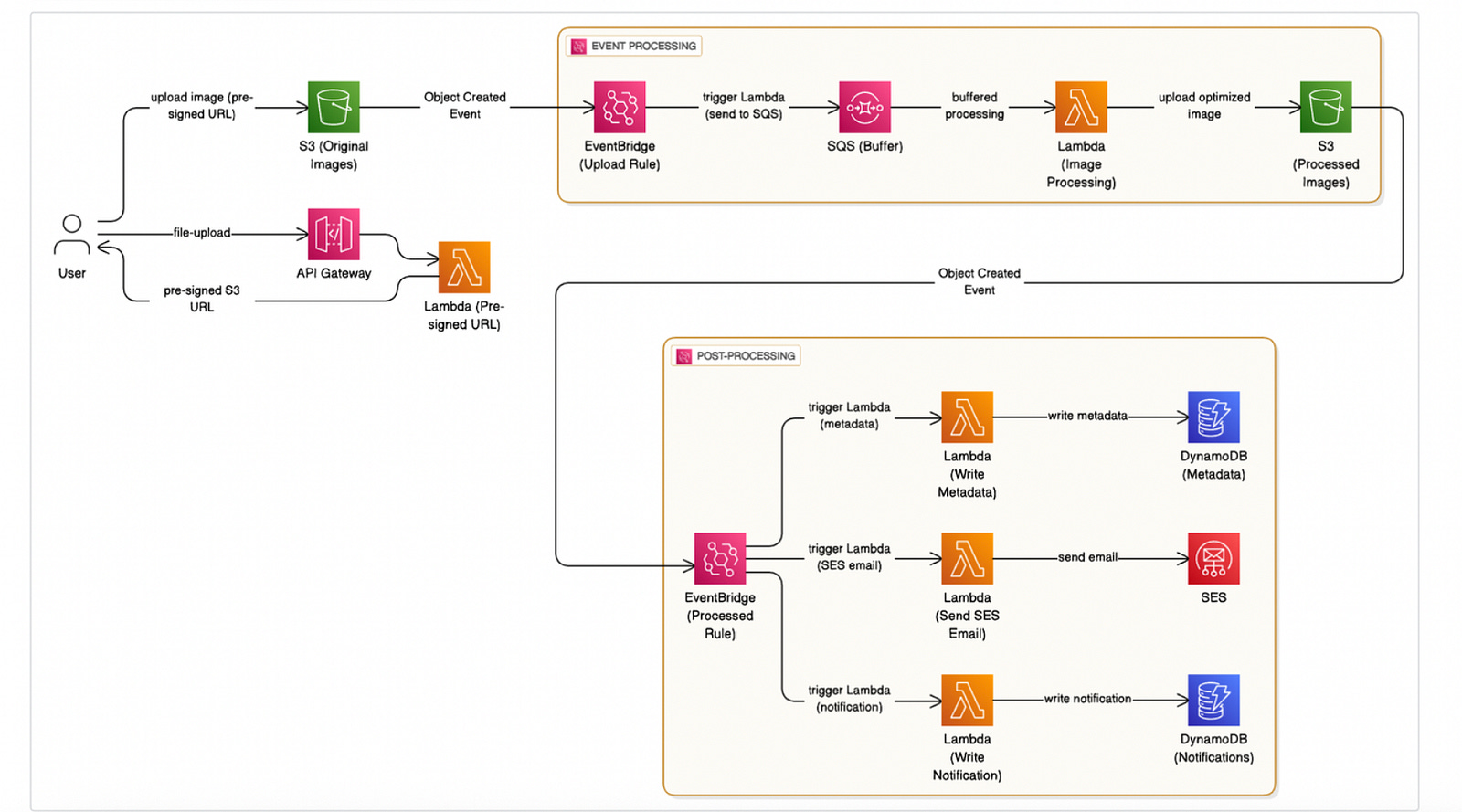
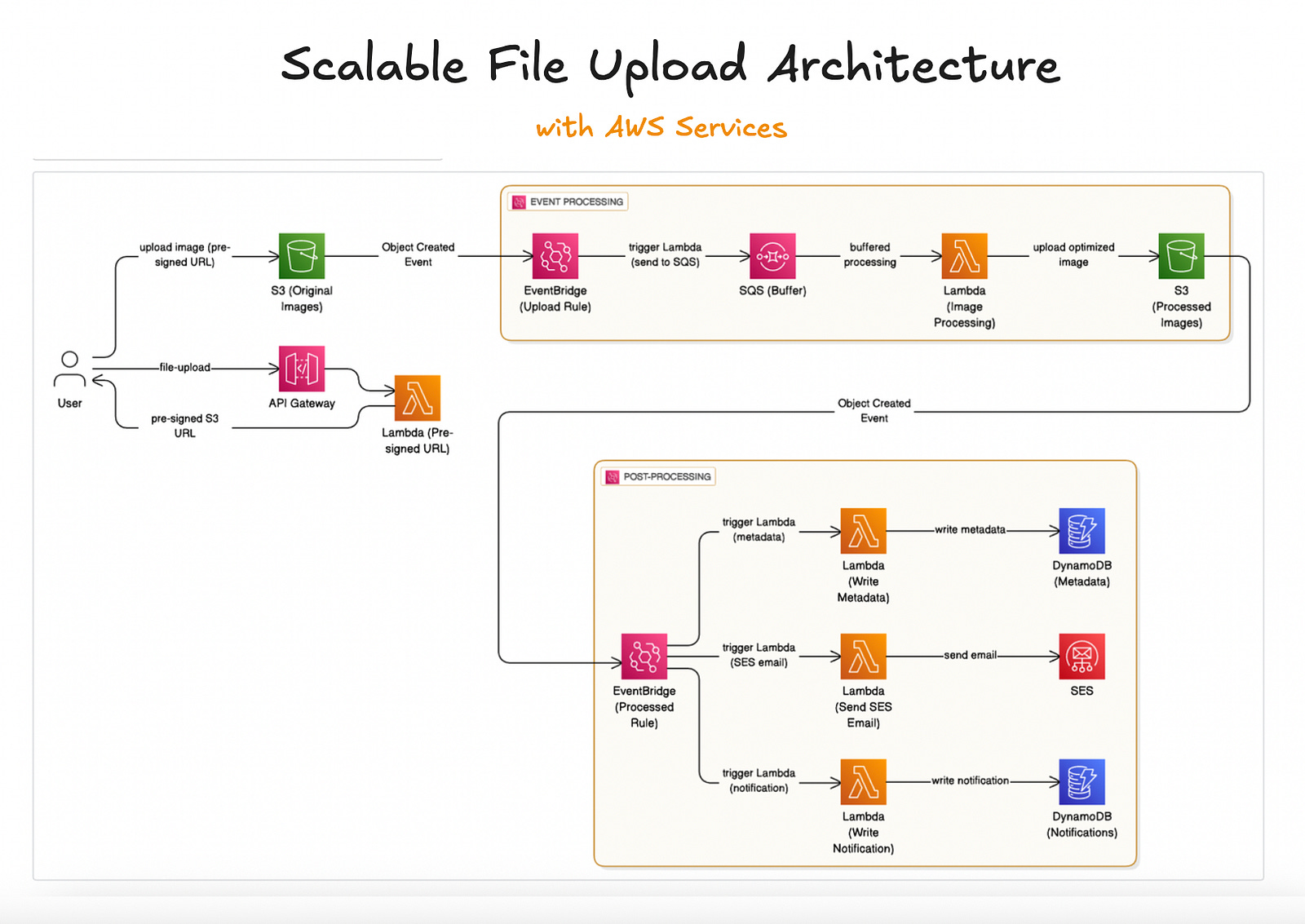
Here’s the high level overview of what the architecture will look like:
From the left-most side: the user starts by calling an API Gateway endpoint (e.g. “/file-upload”).
That endpoint triggers a Lambda function responsible for generating presigned urls.
When the user uploads images with the presigned urls, EventBridge pushes events to SQS to buffer requests
A second EventBridge rule will also do some post-upload actions like notifying the user when the file upload is complete.
DynamoDB is used to store file metadata
SES is used to send emails notifying users of upload completion events.
Let’s now dive deeper into the actual flow of this architecture from the beginning.
Exposing an endpoint with API Gateway
This flow starts with the user wanting to upload an image via the web app client.
Instead of directly uploading the file to S3, they will invoke an API Gateway endpoint which will trigger a Lambda function.
Initial Processing with Lambda
When a request hits API Gateway, it will trigger a Lambda function. This Lambda acts as the first point of logic in our pipeline.
Its role is not to handle heavy image processing just yet, but to generate an S3 presigned url.
The Lambda function validates the input (file type, size, user identity), and generates a presigned url. Once a secure url is generated, it returns it to the client side application.
With this presigned url, the user can now perform a direct file upload to the S3 bucket.
The file is uploaded as it is to a preliminary S3 bucket.
Adding an EventBridge UploadFile Rule
At this point, we can use an EventBridge rule which will detect S3 file upload events to the preliminary bucket.
When an event matches that rule, EventBridge will forward the file upload event payload to an SQS queue.
The reason for having a queue is to be able to buffer concurrent file upload requests at a rate that a Lambda function can tolerate without throttling.
EventBridge will also automatically handle failures with retries (due to network errors or throttling) and send these errors to a DLQ (dead letter queue) where we can connect an SQS queue to stream failed events to be consumed by a Lambda function for further processing on these failed events.
Buffering with Amazon SQS
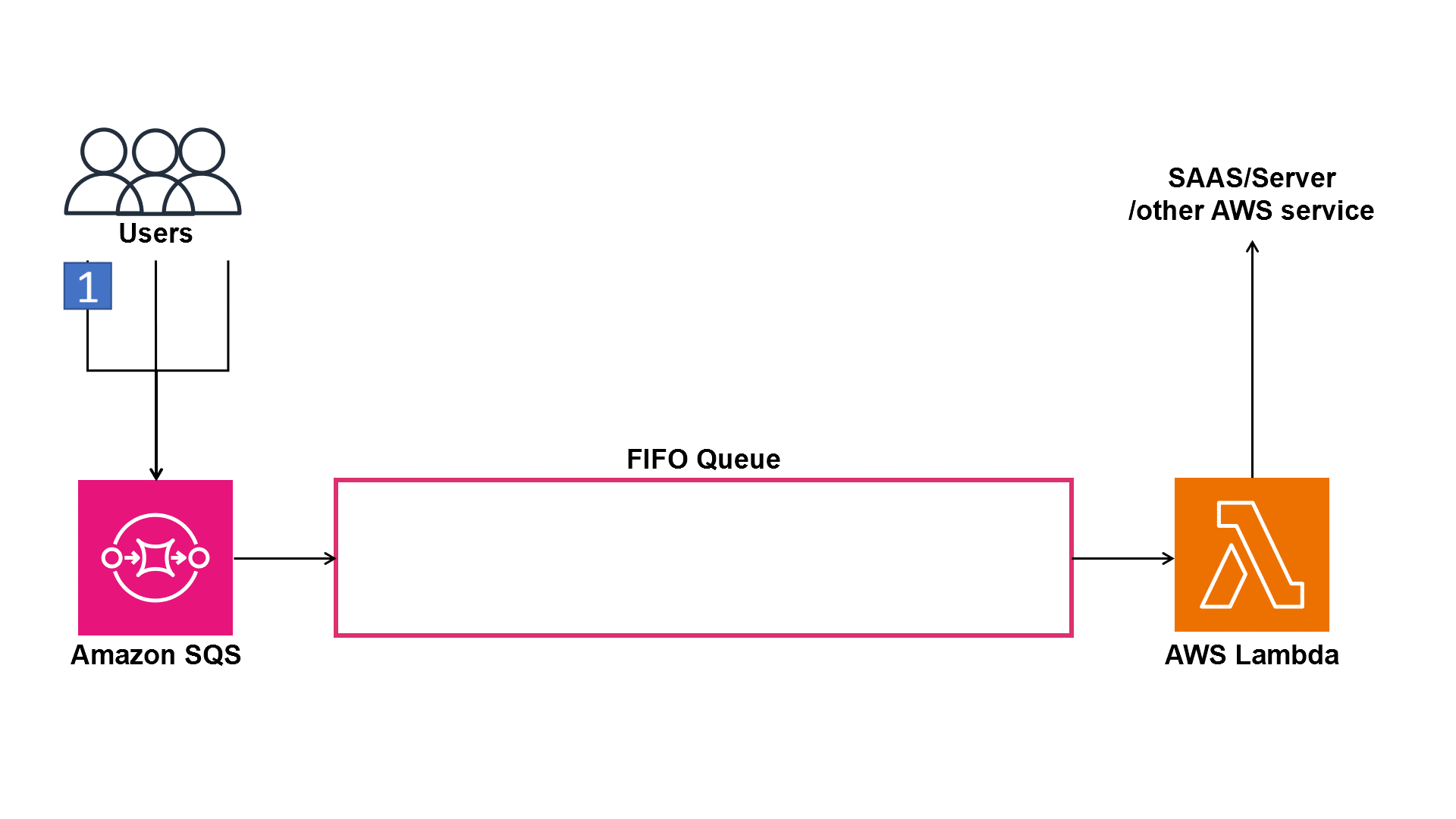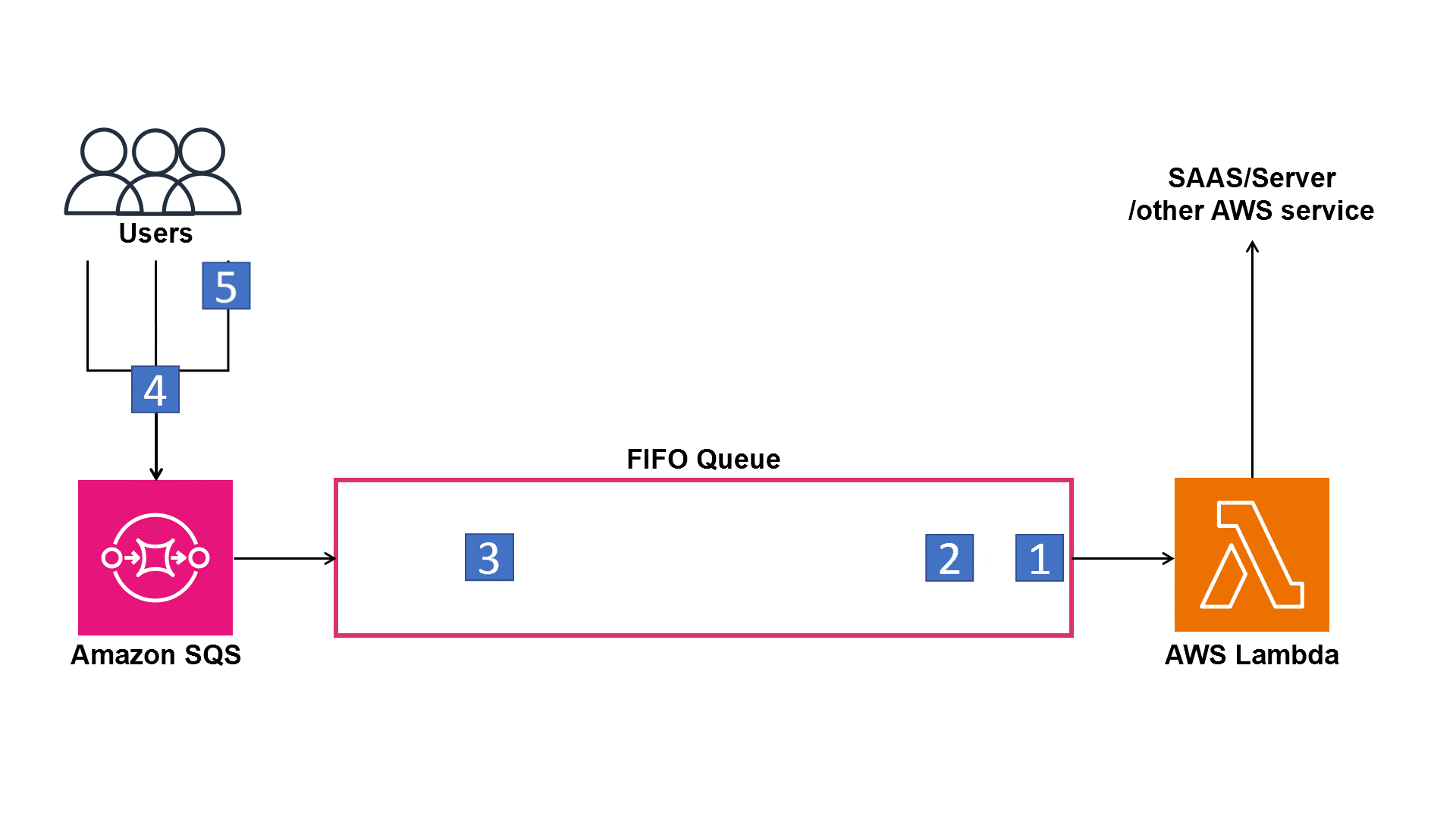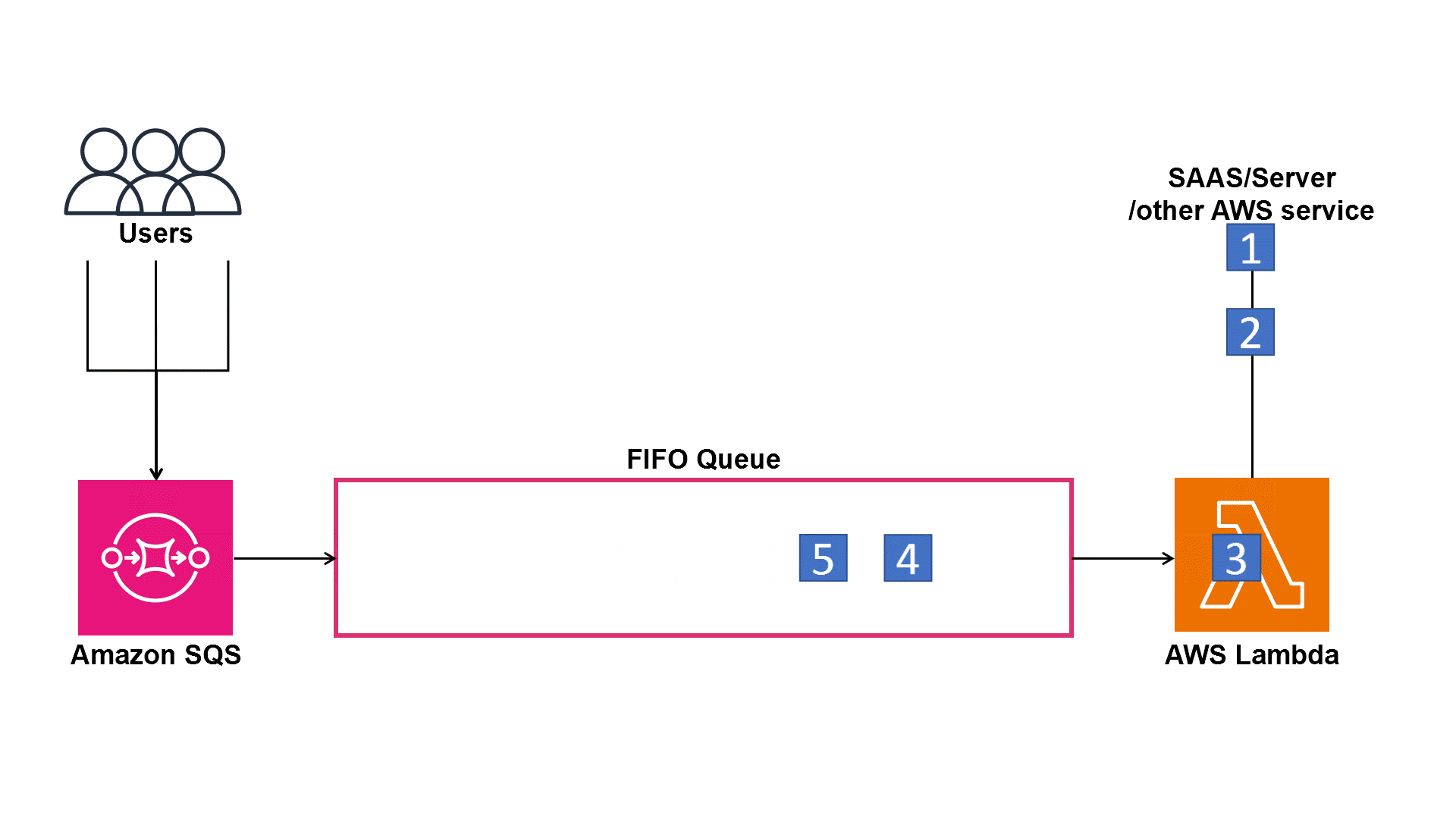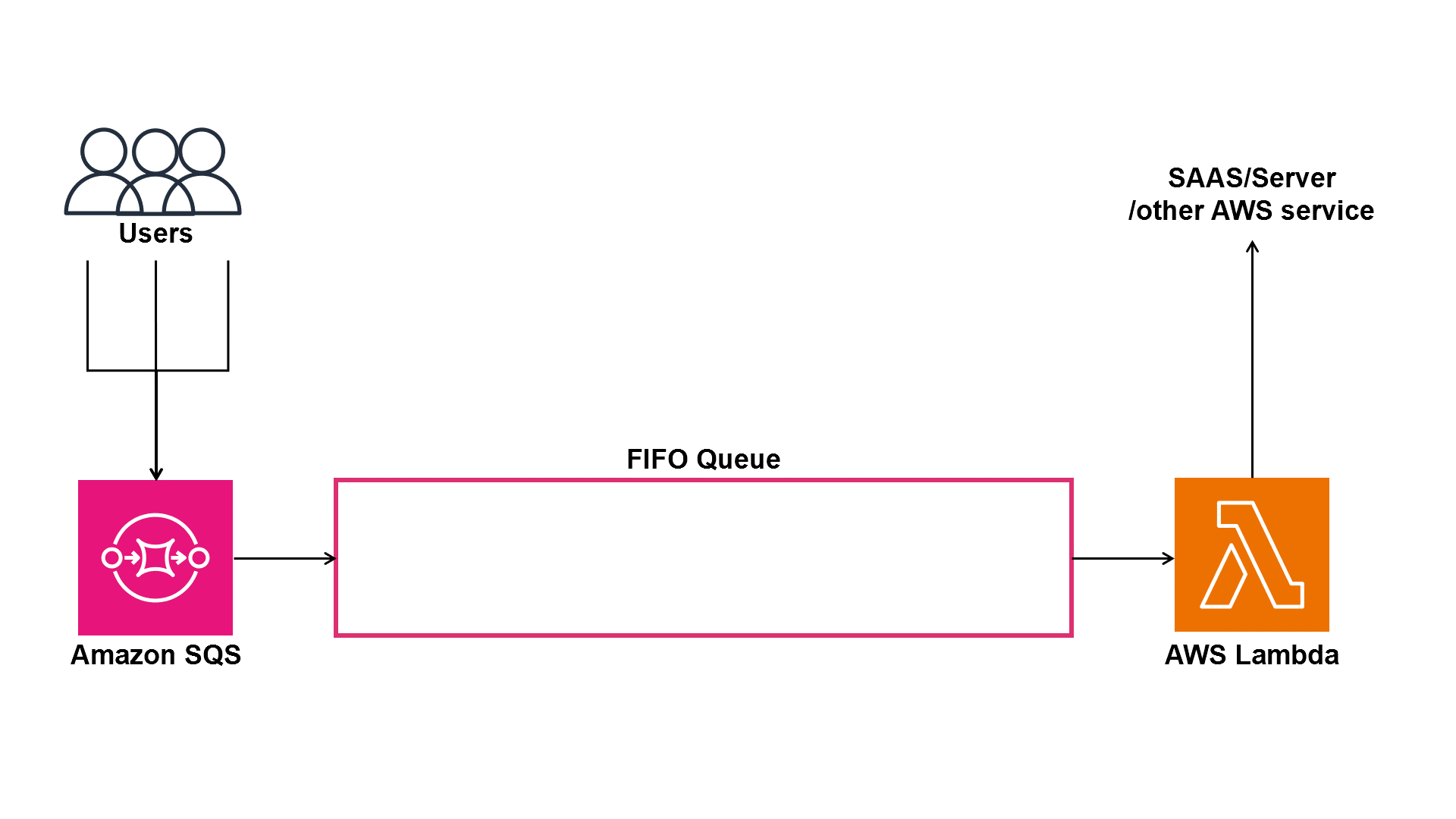
This is where the architecture gains resilience.
By buffering requests in a queue, we ensure that sudden traffic spikes don’t overwhelm our downstream image processing functions.
Even if thousands of users upload files at the same time, the queue smooths out the load and delivers messages at a steady rate to the next Lambda function.
Without a queue, we risk failures, retries, or throttling when Lambda tries to process too many events simultaneously.
Image Processing with Lambda
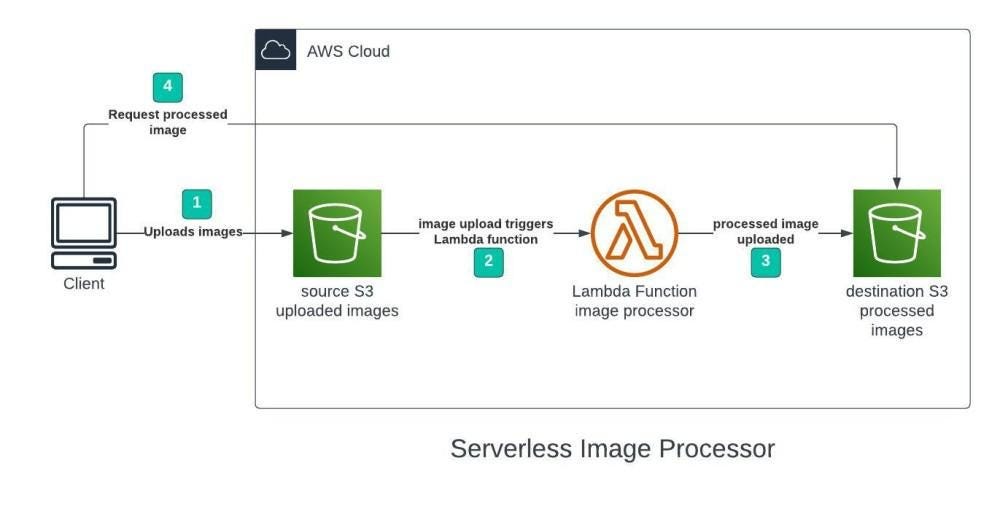
This Lambda function lies at the core of our system’s functionality.
This function subscribes to the SQS queue.
Its job is to actually process the images, compress and resize them to meet application requirements.
This Lambda downloads the original file from the source, performs the compression and transformations, and then uploads the optimized version to a designated Amazon S3 bucket.
Because the Lambda scales automatically with incoming messages from the queue, we can handle virtually unlimited parallel image processing jobs. Each upload is processed independently, keeping the system both scalable and fault-tolerant.
Capturing S3 Events with EventBridge
Once the processed image(s) is uploaded to S3, the system still has work to do. Instead of chaining logic directly into the Lambda, we let EventBridge handle this part.
S3 will again emit an object upload event, which is sent to a second EventBridge rule.
Here, EventBridge acts as an event router to multiple targets: it receives the upload event and applies routing rules to determine which services should be triggered next.
These are the services that will be triggered by EventBridge next:
Store metadata to our DynamoDB database
Send email to user to notify of file upload completion
Send web app or push notification of file upload completion
Adding this Eventbridge layer adds flexibility to our architecture. If new downstream services are needed in the future (e.g. call an AI API to analyze images), we simply create a new EventBridge rule without touching the existing Lambdas.
Metadata Storage with DynamoDB
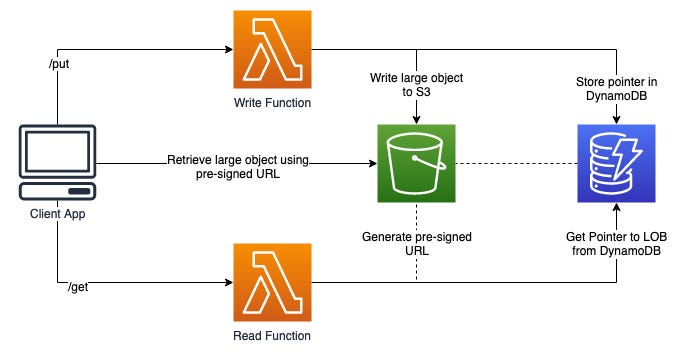
The first EventBridge rule routes the event to a Lambda function that writes the file’s metadata into our DynamoDB table.
Metadata might include file size, dimensions, upload timestamp, and the user who uploaded the image.
DynamoDB is the perfect fit here because it provides millisecond latency and will scale seamlessly with high traffic concurrent requests. This makes it easy for the application to query and retrieve metadata in real time without experiencing performance bottlenecks.
User Notification with SES
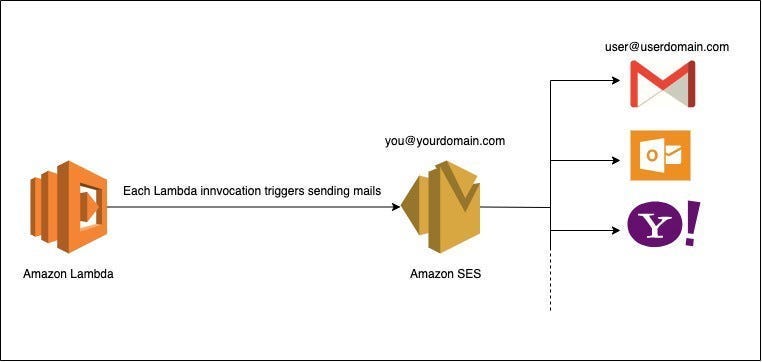
The second EventBridge rule triggers a Lambda that integrates with Amazon SES (Simple Email Service). This Lambda sends an email notification to the user once their image upload has completed.
App Notification with DynamoDB
The third EventBridge rule routes the event to another Lambda function. This one will write a notification item into DynamoDB, which the web app can read to notify the user in real time.
There are several reliable ways that we can do this.
One, the frontend might use an API Gateway websocket to keep a real-time data flow so we get a notification when the item is written to DynamoDB.
We can also use an AppSync GraphQL subscription in the same way.
Another method can be by polling against DynamoDB streams to show the notification item.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!