
How DynamoDB Streams Batch Processing Works
Understanding streams batch processing is essential to using Streams effectively.


I remember when I first started using DynamoDB streams, the data I processed was a mess.
I didn’t understand how Streams worked and it affected the data on my database.
Here was the problem:
My first project that involved streams was about processing user uploaded data to Amazon S3. Everytime a user upload a file, I had a Lambda function that would run some processing on that file, write the file’s metadata to DynamoDB and then upload a modified version of the file to S3.
The issue was some of these user uploaded files would range between a few megabytes to several hundred megabytes. The size limit was 1gb.
In turn, this required me to boost the Lambda function’s memory size from the default 128mb to 256mb (the max memory usage was below this).
But during production often the Lambda functions would timeout even though during my tests they wouldn’t timeout with 1gb file uploads.
What was going on?
The Solution: Streams Batch Processing
The answer to my problem lied with DynamoDB streams and how they work.
When you enable Streams on your DynamoDB table, you have to create a trigger. This trigger needs to be a Lambda function that will be executed when items are added, modified or deleted from your table.
When you add a trigger, you first choose the Lambda function trigger and then you can choose a batch size number.
Here’s the “add a trigger” page:
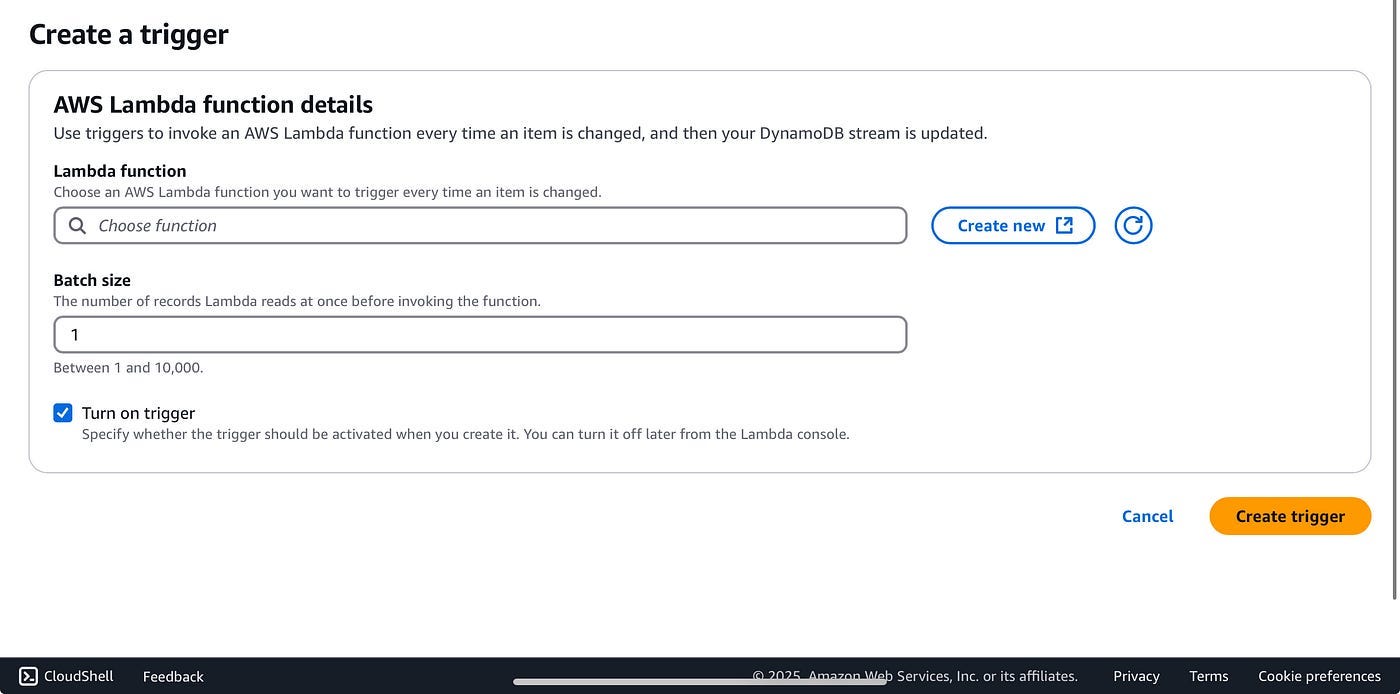
Batch Size
What is Batch size and what does it do?
When items are modified on your DynamoDB tabel, a change stream event is created which lets you invoke a Lambda function to perform further downstream processing.
At the default batch size of 1, the Lambda function waits for just one item to be “streamed” until it is invoked.
This is where it gets interesting.
For scalability, you want to use a higher number so that many items can be processed with one Lambda function invocation.
But the more items the function processes the more time it takes and hence the more memory it needs to process these items.
So finding the right balance between number of items processed by the function is key.
Too little items and your function is called too often, causing potential for bottlenecks, while too many items will cause the function to timeout or overspend on memory (and cost).
As you can guess the problem in my project was that I had set the batch size number to 1000 and the function was timing out.
The solution was simple:
I increased the timeout from 1 minute to 10 minutes
I increased the memory of 128mb to 1gb
I used a smaller batch size number for the Streams processing (20).
The result was no more timeouts — the increase in memory size, timeout was able to accommodate the user uploaded files.
Conclusion
Understanding how DynamoDB Streams works is essential to using them at scale in production.
By adjusting the batch size and increasing the memory and timeout settings, I was able to optimize the Lambda function for processing DynamoDB Streams.
This allowed me to avoid performance bottlenecks and make sure my Lambda triggers was able to support DynamoDB’s Stream data
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedinfor valuable daily posts.
Thanks for reading and see you in the next one!