
Importing Data From Amazon S3 Into DynamoDB
A performant and easy alternative to import large scale data into DynamoDB


A common challenge with DynamoDB is importing data at scale into your tables.
Folks often juggle the best approach in terms of cost, performance and flexibility.
One solution satisfies these requirements quite well: DynamoDB’s Import to S3 feature.
In this article, we’ll explore how to import data from Amazon S3 into DynamoDB, including the native import option provided by AWS and a custom serverless method using AWS Lambda.
Why use Import from S3 feature?
Amazon S3 is commonly used as a data lake or backup storage medium.
You would typically store CSV or JSON files for analytics and archiving use cases.
If you already have structured or semi-structured data in S3, importing it into DynamoDB is a cost-effective and efficient method to migrate that data.
Option 1: Native DynamoDB Import Feature
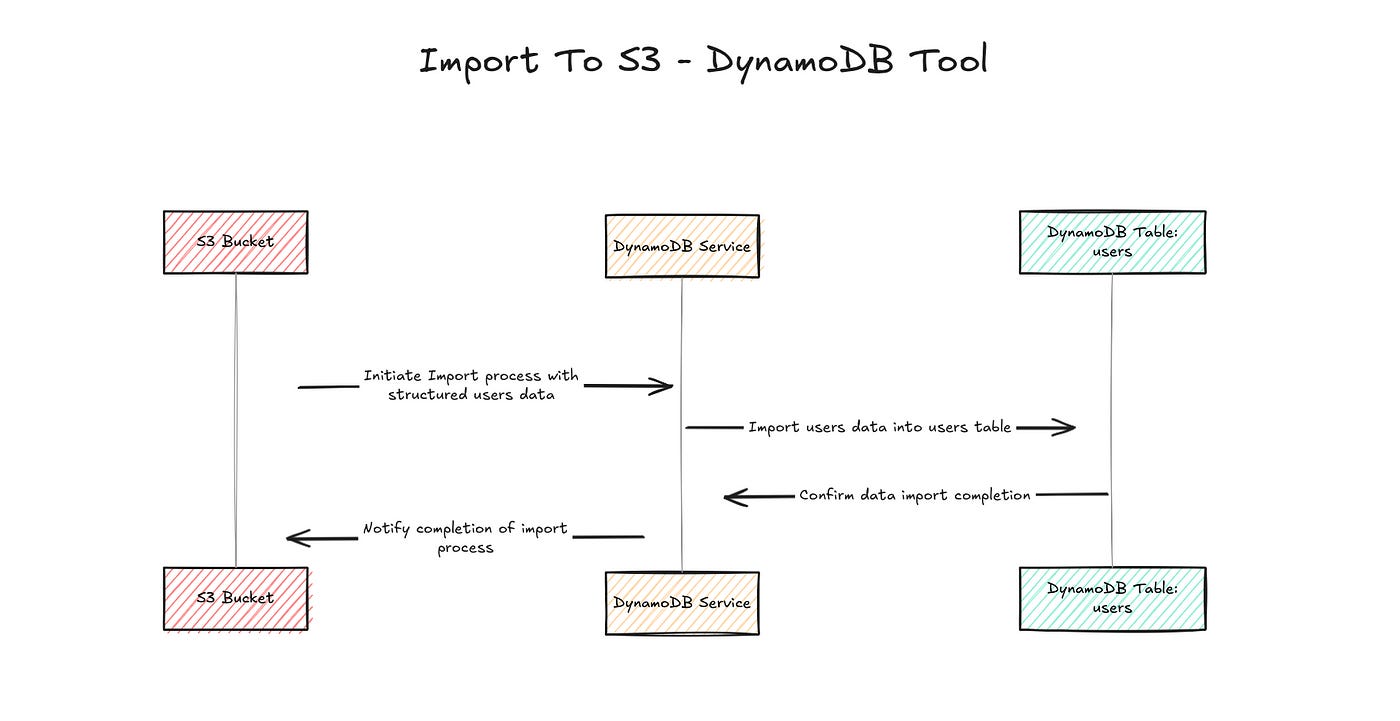
There are two options to import your data from S3 to DynamoDB with AWS.
The first is using the native feature Import from S3 feature to directly import data into a DynamoDB table.
Here’s how to setup your data to use the tool:
Prepare your data in JSON format
Each JSON object should match the structure of your DynamoDB table’s schema (i.e. the right partition and sort keys).
Upload your JSON file to an S3 bucket and make sure you provide access permissions to DynamoDB.
Once you have set up your data properly, you can start importing it into DynamoDB.
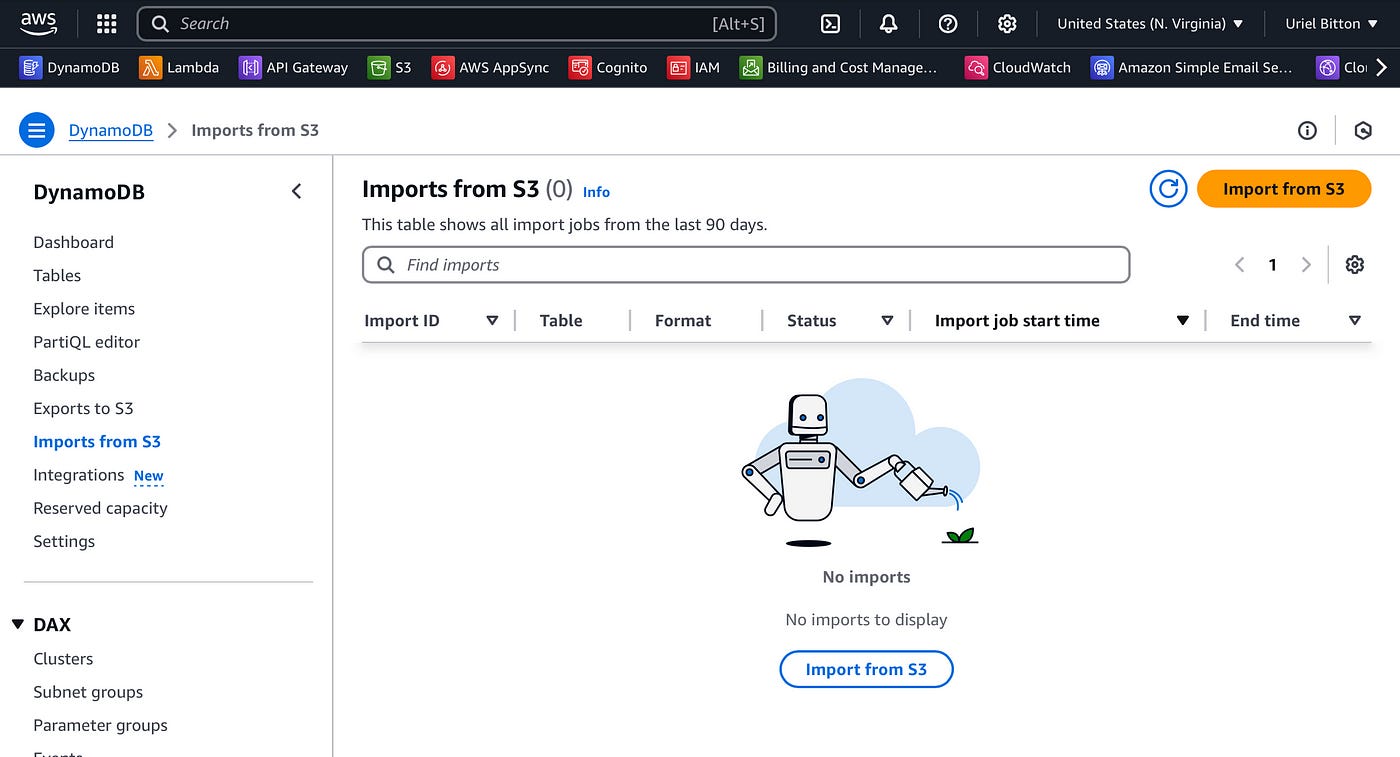
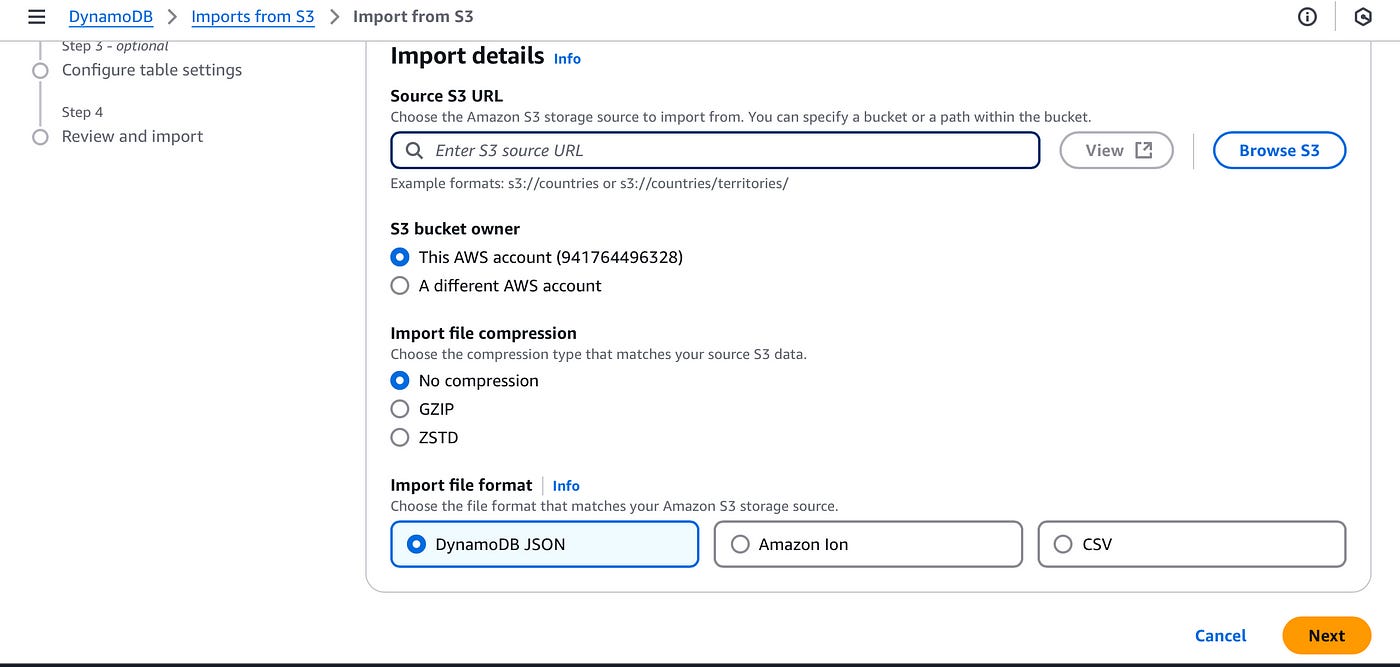
In the DynamoDB console, click on import to S3. Here you can choose the S3 bucket and import file format (choose DynamoDB JSON).
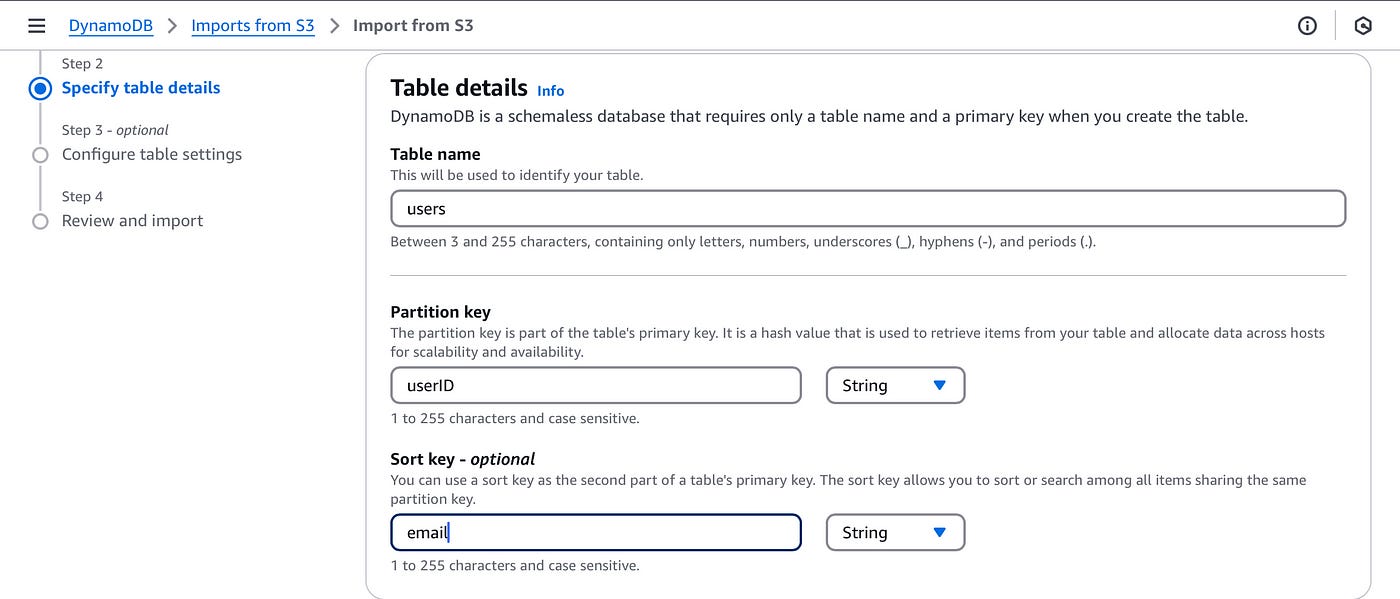
Next, choose your target DynamoDB table and make sure to properly define your correct partition and sort keys.
Click on start import job to start importing the data to DynamoDB.
Option 2: Serverless Import with Lambda

The custom Lambda solution uses a different approach.
It provides more a more flexible and real-time flavoured import pipeline using S3 Event Triggers.
The architectural overview of this pipeline (image diagram above):
Files are uploaded to S3
S3 triggers a Lambda function
The Lambda function reads the file, processes each (JSON) item and writes them to DynamoDB
To implement this pipeline you must enable event notifications for PutObject operations in your S3 bucket.
Then create a Lambda function that is triggered by this S3 bucket on Put events.
Here’s the sample code for the Lambda function:
import { S3Client, GetObjectCommand } from '@aws-sdk/client-s3'
import { DynamoDBClient, PutItemCommand } from '@aws-sdk/client-dynamodb'
import { Readable } from 'stream'
const s3Client = new S3Client({})
const ddbClient = new DynamoDBClient({})
const TABLE_NAME = “users”;
const streamToString = async (stream) => {
const chunks = []
for await (const chunk of stream) chunks.push(chunk)
return Buffer.concat(chunks).toString('utf-8')
}
export const handler = async (event) => {
try {
const record = event.Records[0]
const bucket = record.s3.bucket.name
const key = decodeURIComponent(record.s3.object.key.replace(/\+/g, ' '))
const s3Response = await s3Client.send(
new GetObjectCommand({ Bucket: bucket, Key: key })
)
const bodyString = await streamToString(s3Response.Body)
const jsonData = JSON.parse(bodyString)
if (!jsonData.pk || !jsonData.sk) throw new Error('Missing pk or sk')
await ddbClient.send(
new PutItemCommand({
TableName: TABLE_NAME,
Item: {
pk: { S: jsonData.pk },
sk: { S: jsonData.sk },
...Object.entries(jsonData).reduce((acc, [k, v]) => {
if (k !== 'pk' && k !== 'sk') acc[k] = { S: String(v) }
return acc
}, {})
}
})
)
return { statusCode: 200, body: 'Success' }
} catch (err) {
console.error(err)
throw err
}
}The benefits of this approach is that it handles continued file uploads to S3, not only past uploads.
Furthermore, you have more flexibility to apply transformations to your data, and use other formats than what the import from S3 tool supports.
It is also quite scalable and integrates easily with AWS Lambda.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!