
The Different NoSQL Database Types And When To Use Them
Understand which NoSQL database will best fit your application to maximize scalability and efficiency

When we think of databases, the first thing that often comes to mind is the classic relational database.
Rows and tables, primary keys and joins, and the familiarity of SQL.
But as applications scale, evolve, and demand new levels of flexibility and performance, traditional relational databases don’t always hold up.
That’s where NoSQL databases come in.
NoSQL databases are designed to handle unstructured or semi-structured data at scale.
They offer high availability, horizontal scalability, and flexible schemas.
But NoSQL doesn’t solve every database problem.
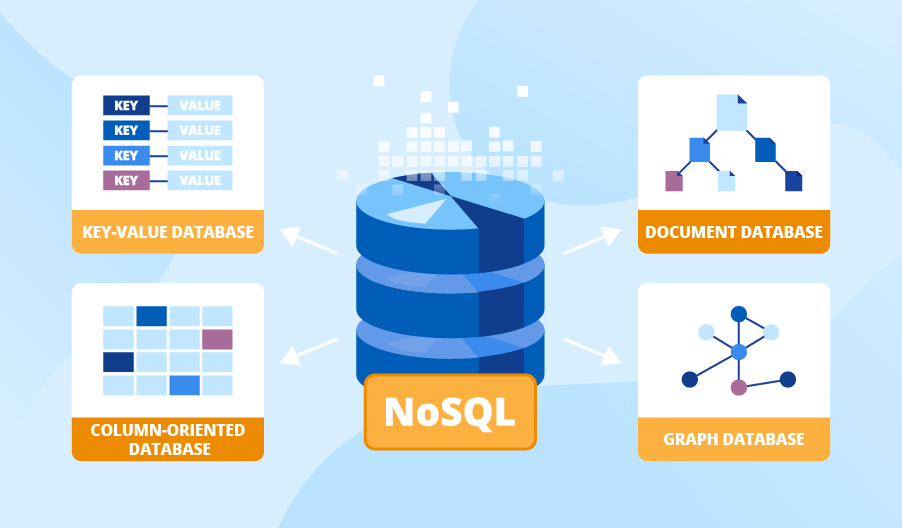
In fact, there are four main types of NoSQL databases, each optimized for different kinds of workloads.
In this article, we’ll break down the four primary NoSQL database types:
document databases
key-value databases
column-family databases
and graph databases
These will help you understand when and why to use each.
1. Document Databases

Document databases are best for content management systems, product catalogs, mobile apps, and event logs.
Some popular options include:
MongoDB
Couchbase
Amazon DocumentDB
Firebase Firestore
Document databases store data as JSON or BSON documents. Each document is a self-contained unit of data that can contain nested structures like arrays and sub-documents.
Unlike relational databases, there’s no need to define a fixed schema up front. Each document in a collection can have a different structure.
This flexibility makes document databases great for apps where your data model changes often.
For example, in an e-commerce platform, different product categories may require different fields. A document database lets you store all of them in the same collection without having to change your schema.
2. Key-Value Stores

These are good for caching, session management, feature flags, and user preferences
Some popular options are: Redis, DynamoDB, Riak, Memcached.
Key-value databases are the simplest form of NoSQL databases.
Data is stored as key-value pairs, where the key is a unique identifier and the value is an opaque blob that the database doesn’t interpret.
This simplicity translates to speed.
Key-value stores are really fast and scale horizontally and easily.
This makes them a good use case for high-performance workloads like caching.
For example, Redis is frequently used to cache the results of expensive database queries, reducing load on primary databases and improving your app’s speed.
However, their simplicity is also their limitation.
Key-value stores aren’t ideal for applications that require rich querying capabilities or need to access specific fields within a stored value.
Use them when
- Speed and scalability are top priorities
- You have simple lookup patterns based on IDs
- Your data doesn’t need complex relationships or queries
3. Column-Family Databases

Ideal use cases for column-family databases are time-series data, analytics platforms, recommendation engines.
Some popular options are Apache Cassandra, ScyllaDB, HBase.
Column-family databases store data in tables, rows, and columns, but unlike relational databases, each row can have a different set of columns.
Data is stored in column families, which allow you to access related data together very efficiently.
This structure is best for write-heavy and read-optimized workloads.
Here’s an example:
Imagine a time-series application where you collect millions of sensor readings. A column-family database allows you to store large amount of data with high write throughput and retrieve it efficiently based on time ranges.
e.g. Get the sensor readings for the past month, past 6 months, or just today.
Column-family databases are also highly scalable and fault-tolerant.
However, data modeling in column-family databases requires more upfront thinking. It requires denormalization and access pattern-based design (as we see similarly with DynamoDB).
4. Graph Databases
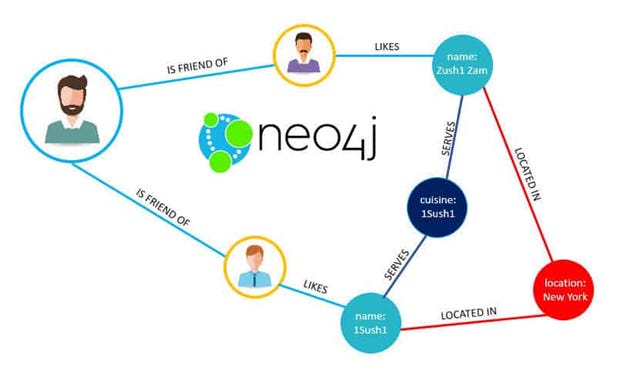
Graph databases work great for social networks use cases, recommendation systems, and fraud detection systems.
Some well known graph database systems include: Neo4j, Amazon Neptune, ArangoDB.
Graph databases store data in nodes and relationships (edges).
They are optimized for queries that explore complex relationships, like finding the shortest path between two nodes or determining a user’s second-degree connections (LinkedIn use case).
Traditional relational databases struggle with deeply connected data, especially when joins become expensive at scale. Graph databases, on the other hand, are built to solve this issue specifically.
For instance, in a social media platform, finding mutual friends or suggesting new connections based on a shared network is a common task.
Graph databases make these kind of traversal queries fast and efficient.
However, graph databases aren’t ideal for bulk transactions or simple key-based lookups, as relational and key-value databases are.
They work best when relationships are critical in your data model.
Graph databases are particularly useful when relationships between data are central to your application. Or you need to perform frequent traversals or pathfinding like with social network or geographical maps workloads.
Choosing the Right NoSQL Database

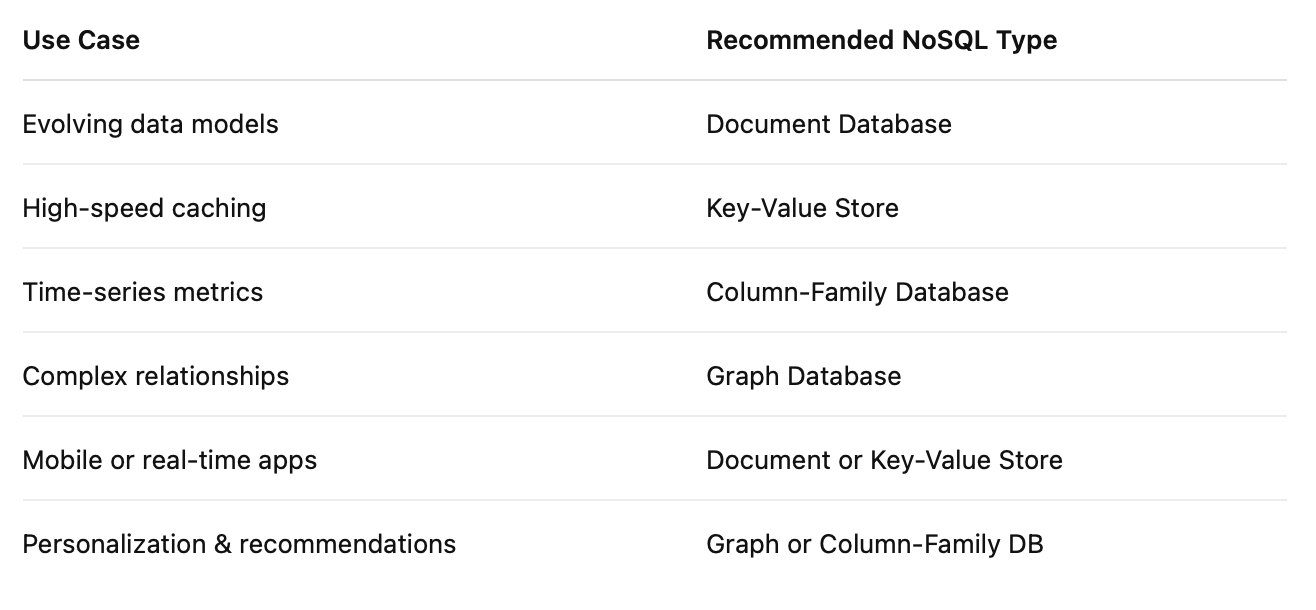
So how do you choose the right NoSQL database?
Well the answer is one i frequently give: It all depends on your application’s needs:
I’ve summed up a high level overview of typical use cases along with their most ideal database solution below:
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!