
The Journey Of A DynamoDB Query: A Behind The Scenes Adventure
An easy-to-understand journey of what happens when you make a query in DynamoDB

Have you ever wondered what happens when you invoke DynamoDB’s query API?
Maybe not, but it would still be interesting to know how the internal cogs of DynamoDB turn and grind to retrieve data from your table.
In this article, let’s dive into this journey and see how it works behind the scenes, in a simplified manner.
When you execute a DynamoDB query, you’re tapping into a meticulously engineered system that is designed for low latency, scalability and efficiency.
Let’s take a look at what goes on step by step.
1. The Request is made

A DynamoDB starts with a request payload from the client.
Here’s what that includes:
A table name to search in.
A partition key: a required key that defines in which storage partition to look for the data.
A sort key condition: a condition that is used to refine results within the partition.
Filters: An optional condition applied after fetching the results to filter for a specific attribute value.
Here’s an example query:
"TableName": "Orders",
"KeyConditionExpression": "customerId = :customer_id AND orderDate BETWEEN :start_date AND :end_date",
"ExpressionAttributeValues": {
":customer_id": "123",
":start_date": "2024-11-01",
":end_date": "2024-12-31"
}2. The Request Router
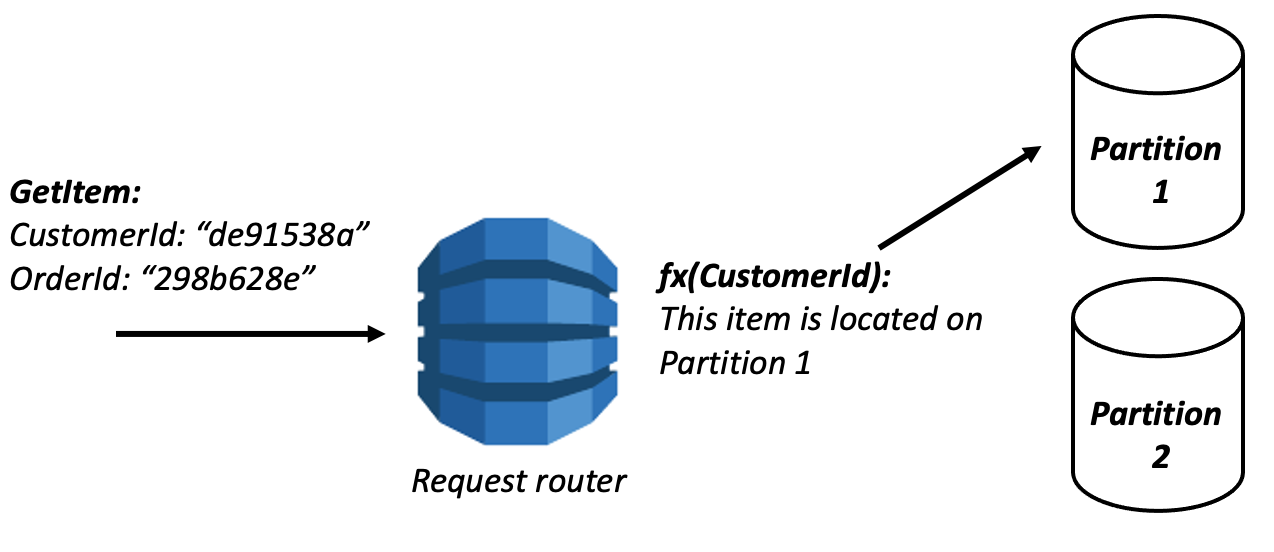
Before your query even touches DynamoDB’s storage layers, it passes through the Request Router, DynamoDB’s entry point.
Here’s how it processes your requests:
Routing the Request: When the request is received by DynamoDB’s endpoint, it routes it to the appropriate server. AWS regions and availability zones are considered to ensure the request is handled by the closest and most reliable node.
Authentication and Authorization: DynamoDB verifies the caller’s credentials using IAM policies to ensure the request has the necessary permissions. If unauthorized, the request is denied immediately.
Throttling Check: DynamoDB enforces provisioned throughput limits (read/write capacity) or evaluates the on-demand mode limits. If a request exceeds these limits, it is throttled, returning a ProvisionedThroughputExceededException.
3. Parsing and Validating the query
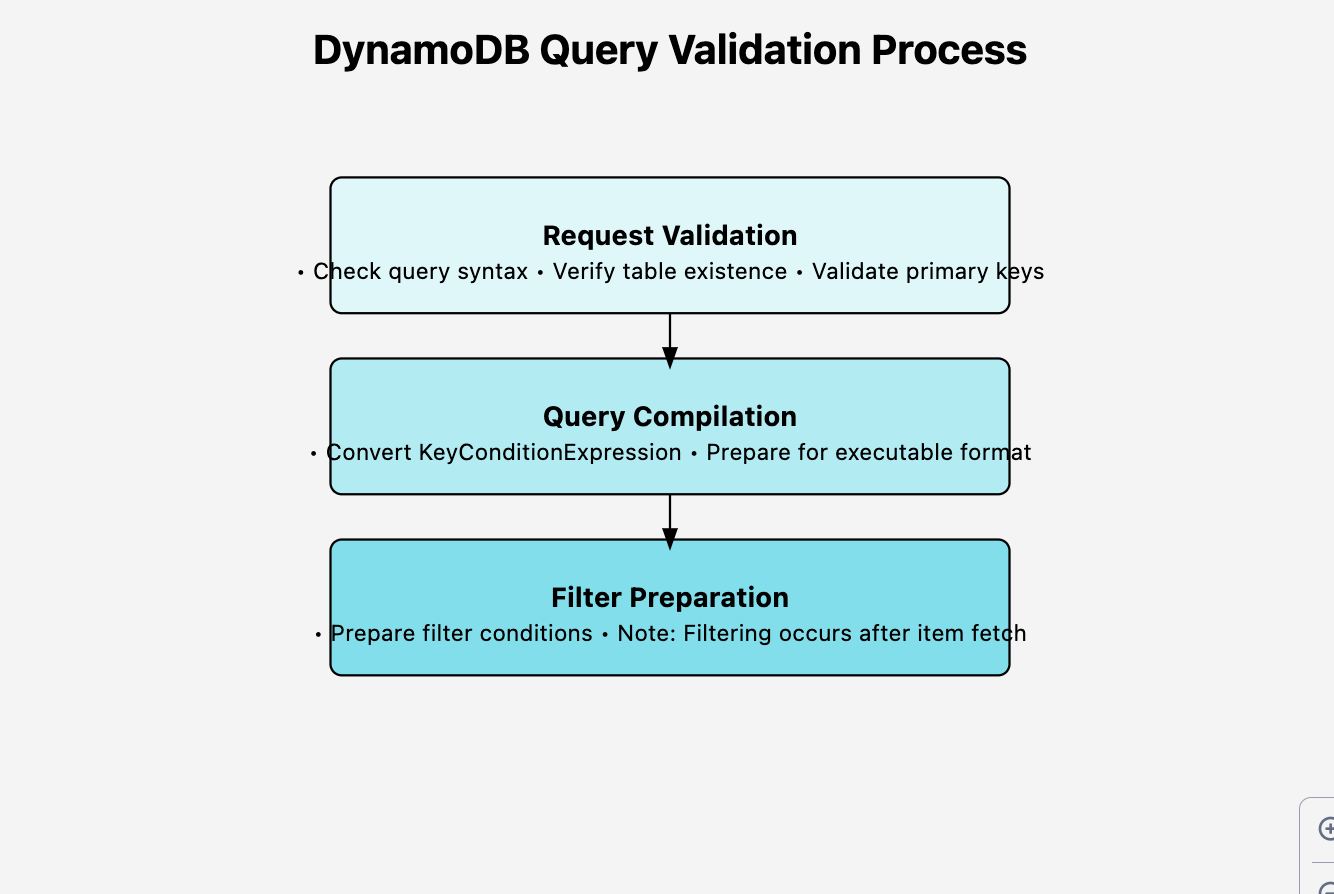
Before moving to the next step, DynamoDB performs the following validations:
It will validate the request — it checks the syntax of the query, checks if the table exists and ensures the primary keys and attributes are valid.
It compiles the query — it converts the KeyConditionExpression into an executable format.
It prepares the filters and discards the items that don’t meet the filter condition (* however the filtering is done after all the items are fetched).
4. Finding the right partition
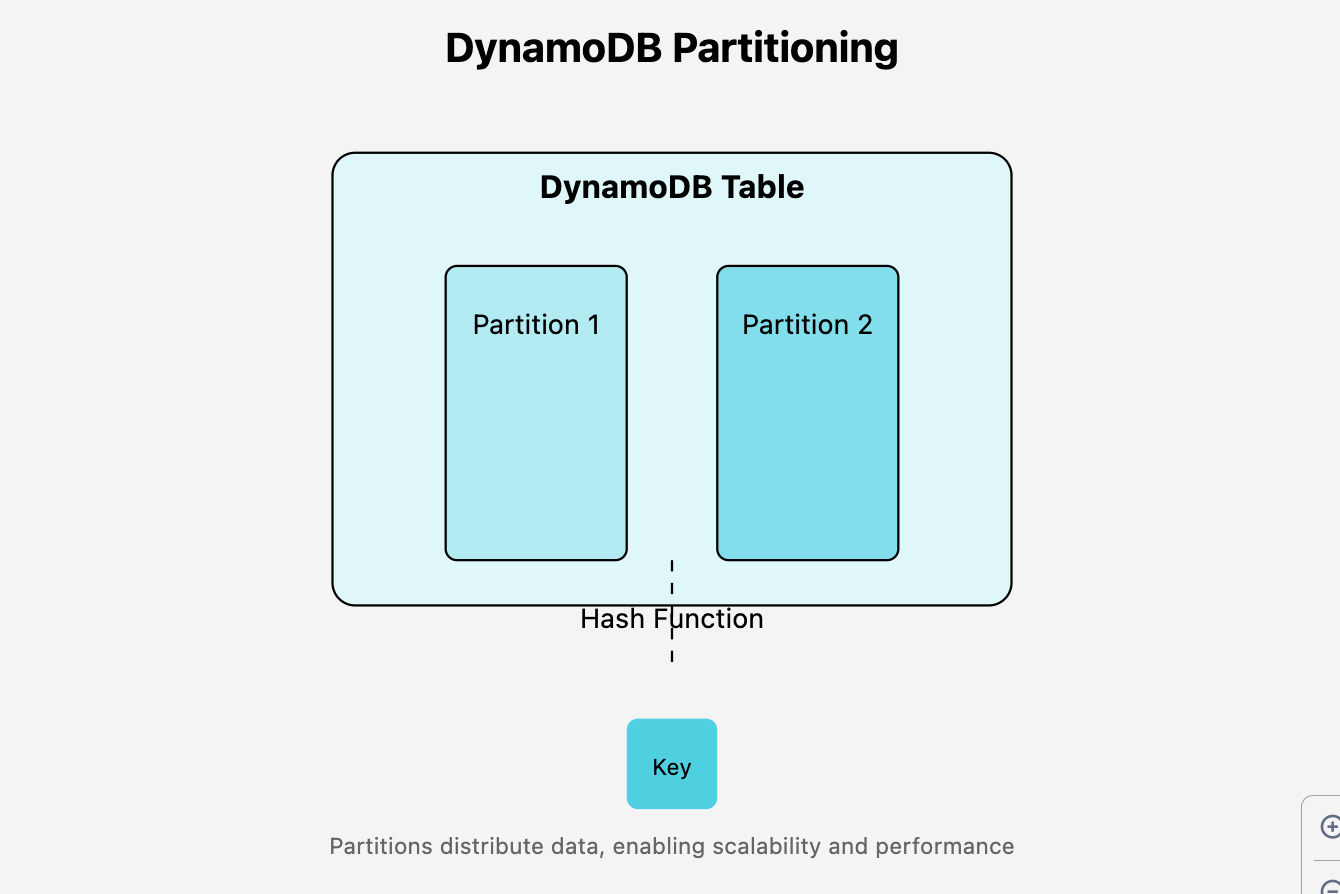
Every DynamoDB table is internally divided into partitions.
A partition is a data storage node — each node contains a part of your data.
When you query with a partition key, DynamoDB uses a hash function to locate the exact partition containing your data.
As your table grows DynamoDB will automatically add partitions and distribute the load for best performance.
This is why a well-designed partition key ensures better data scalability, and on the other hand, ignoring this leads to hot partitions.
5. Navigating the partition with sort keys
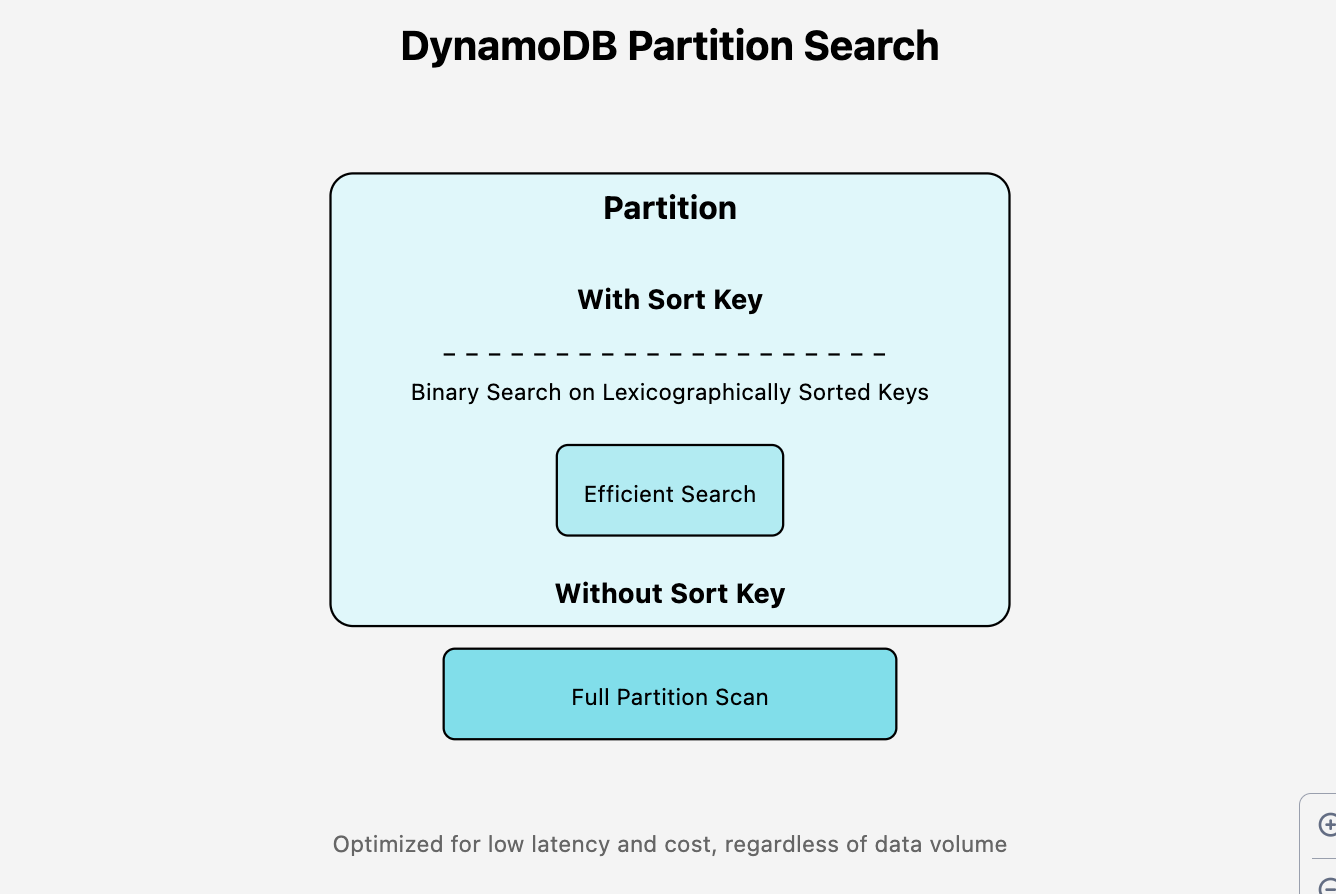
Once the partition is located, here’s what happens:
If a sort key condition is provided, DynamoDB performs a binary search on the sort keys which are stored lexicographically.
Without a sort key, DynamoDB scans the entire partition.
Queries are made efficiently lowering latency and costs, no matter how much data is stored on your database.
6. Reading from storage
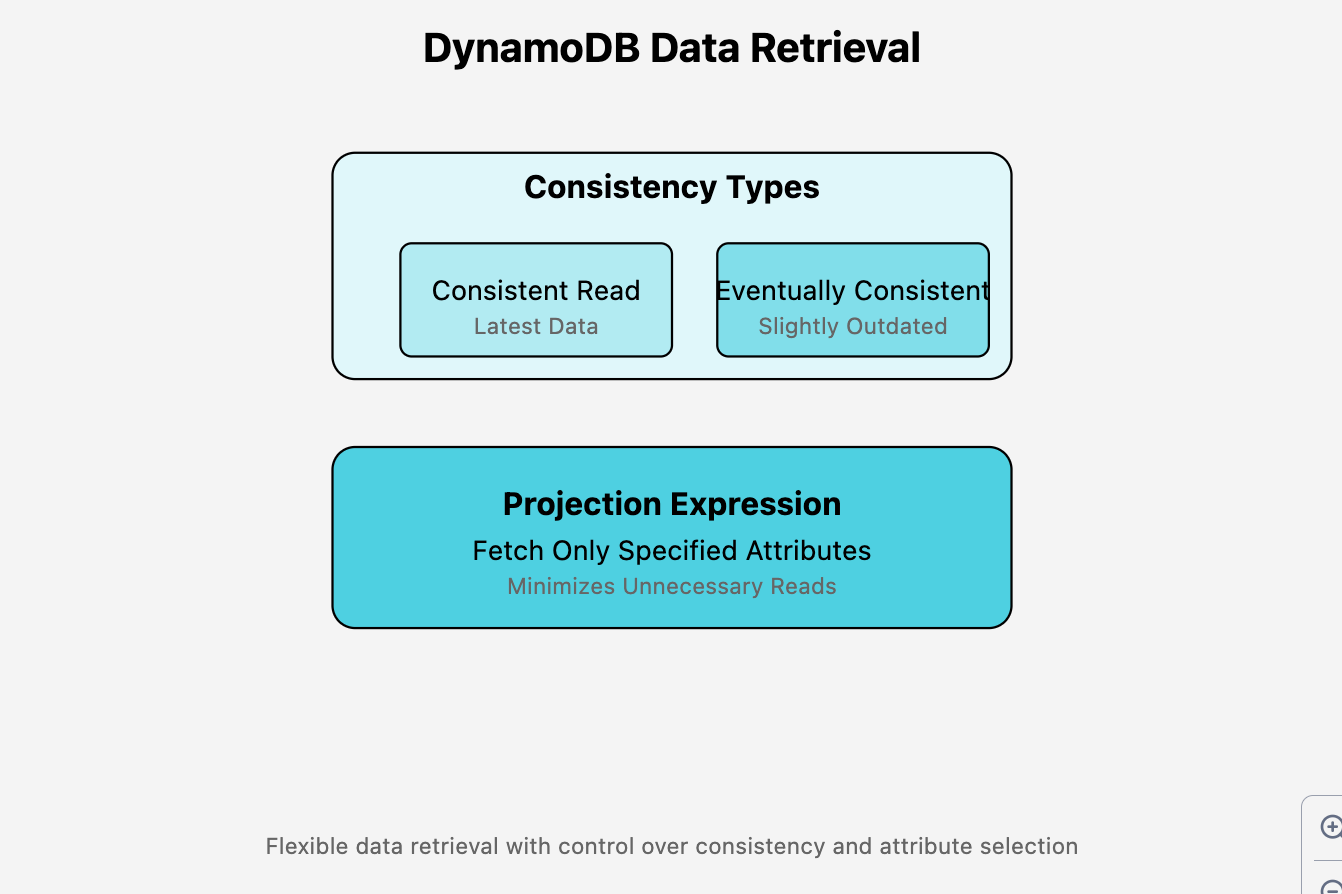
After it identifies the relevant items, DynamoDB fetches the actual data.
Depending on your request settings — consistent or eventually consistent queries — DynamoDB will retrieve the latest version of the data or (infrequently) a slightly outdated version of the data (faster and cheaper).
If a ProjectionExpression is provided, DynamoDB only fetches the attributes you specify to get back, which minimizes unnecessary reads.
7. Applying filters (Post-query processing)
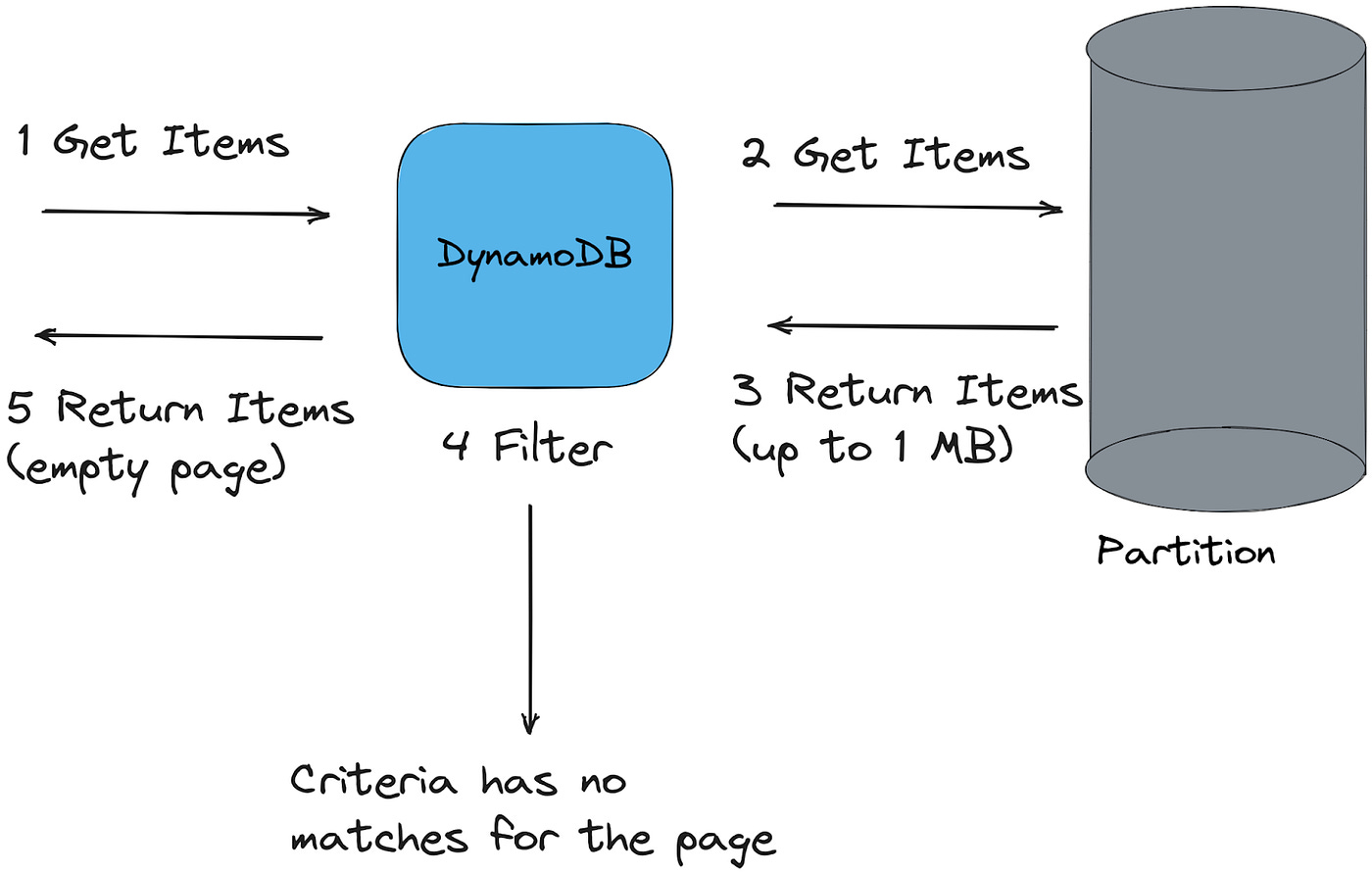
Once the raw results are retrieved, DynamoDB applies any optional filter expressions.
Unlike the KeyConditionExpression, which limits the data DynamoDB reads, filters are applied after data retrieval.
For example, if your query retrieves 100 items but the filter excludes 90 of them, your query will return 10 items but will still be billed for reading all 100 items.
8. Response is returned
After filtering, DynamoDB will package the results by converting the raw data into a JSON response.
It will then add the details of the response such as:
the items returned.
total number of items read.
item count.
consumed capacity.
Here’s an example response:
{
"Items": [
{"orderId": "A123", "total": 100.0},
{"orderId": "B456", "total": 150.0}
],
"Count": 2,
"ScannedCount": 10,
"ConsumedCapacity": {
"TableName": "Orders",
"CapacityUnits": 5
}
}At this step, DynamoDB will also process the Limit attribute if one is provided and in return provide a LastEvaluatedKey for you to create a pagination of your data.
Conclusion
Understanding how DynamoDB processes a query is key to designing more scalable, performing, and cost-efficient databases.
By breaking down each step — from request routing and validation to partition navigation and result filtering — you can optimize your queries for better outcomes.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!