
Understanding Strong Vs Eventual Consistency In DynamoDB
Understanding the differences between strong and eventual consistency in DynamoDB and what these mean for our data.


What is Consistency in DynamoDB?
Consistency is an important concept you need to understand and consider in databases.
At a general level, consistency refers to whether a particular read operation receives all write operations that have occurred prior to the read. [1]
In essence, a read operation may not always receive the latest write data. To understand why this is, let’s understand how DynamoDB works internally.
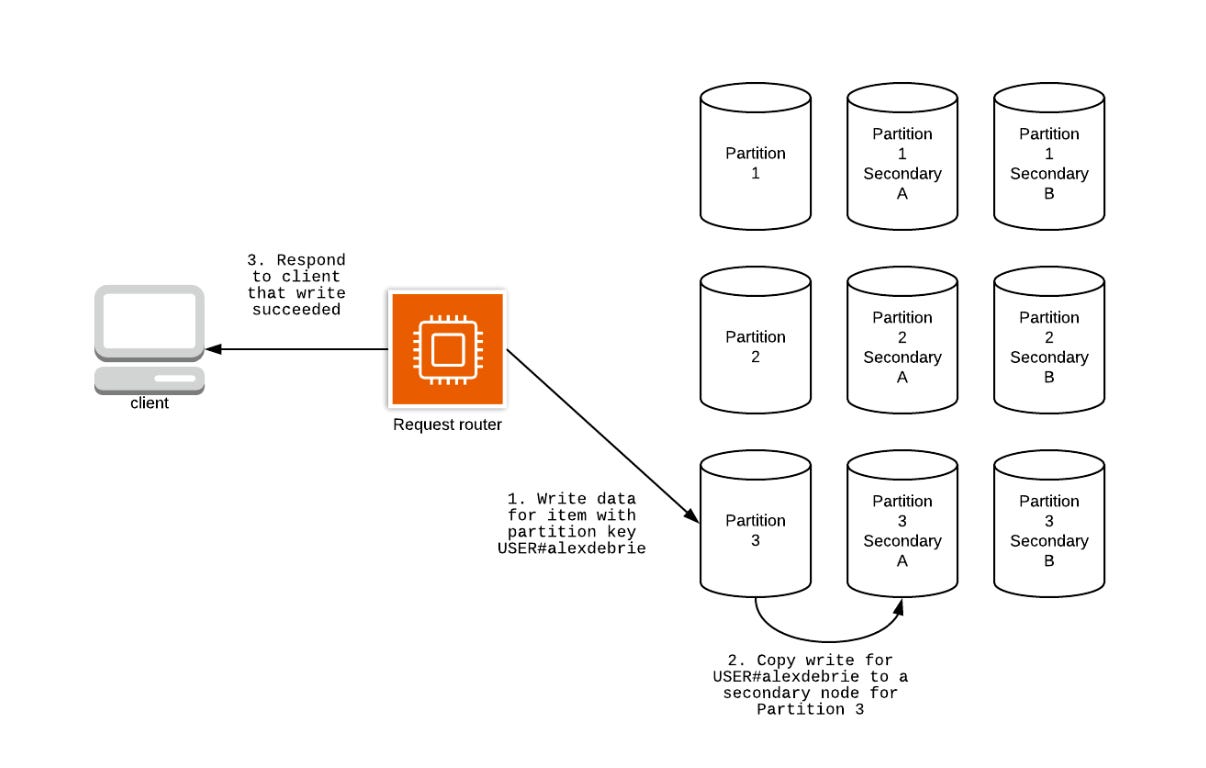
To be able to scale horizontally, DynamoDB splits its data across multiple partitions. This allows for fast performance regardless of data size.
When you write data to DynamoDB, a request router authenticates your request, hashes the partition key, and sends it to the correct primary node.
The primary node commits the write and saves it to one of two secondary nodes for redundancy in case of failure.
After it acknowledges a successful write, the primary node asynchronously replicates the data to a third node.
Each partition has three nodes (a primary and two secondary nodes), to help provide fault tolerance and balance read requests.
However, since writes are replicated asynchronously, secondary nodes may sometimes be slightly behind the primary, which results in reading outdated data from a secondary node.
This concept leads to the idea of eventually consistent reads.
What is Strong Consistency?
With strong consistency, all items that are read from your table will have the latest writes that occurred before the read operation.
If you have a table with high concurrency and you read data that was just milliseconds updated by another user, your read will still show the latest version.
What is Eventual Consistency?
With eventual consistency, it can happen that items you read from a table can have slightly stale data.
If another user modifies or deletes this data just before you read it, DynamoDB can temporarily return the old version of this data.
Strong Vs Eventual Consistency
When do you need to consider the choice between using strong or eventual consistency?
There are two situations:
First, when reading data from your base table you are able to choose between strong or eventual consistency.
By default, DynamoDB makes all reads eventually consistent, saving you in costs — eventual consistency consumes half the capacity of a strongly consistent read.
To choose a strongly consistent read you can add the attribute ConsistentRead = true in your query.
The second case is when you create a secondary index.
A local secondary index will allow you to make strongly consistent reads, returning updated data.
A global secondary index enforces only eventually consistent reads.
Conclusion
Understanding the differences between strong and eventual consistency is crucial for managing how data is read in DynamoDB.
Strong consistency guarantees that all reads reflect the latest write, while eventual consistency may sometimes return stale data but offers cost savings by using half the capacity units.
When designing your DynamoDB tables and indexes, it’s important to carefully choose the appropriate consistency model based on your application’s needs.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!