
Using Reserved Vs Unreserved Concurrency in AWS Lambda
The pros and cons of using reserved and unreserved concurrency in your Lambda functions


AWS Lambda has a powerful feature for configuring the scalability of your serverless functions.
It offers two types of concurrency provisioning for your functions:
Reserved concurrency
Unreserved concurrency
Understanding the difference between both and how to provision them correctly is key to scalable serverless functions.
What is Concurrency?
Concurrency is what defines how many instances (or copies) of your Lambda function can be invoked simultaenously.
In the concurrency configuration, you can choose this number of concurrency.
For example, if you choose 10 units of reserved concurrency, this means your function can be invoked 10 times at the same time.
If an eleventh invocation is requested for this function, it will be throttled.
Reserved vs Unreserved concurrency
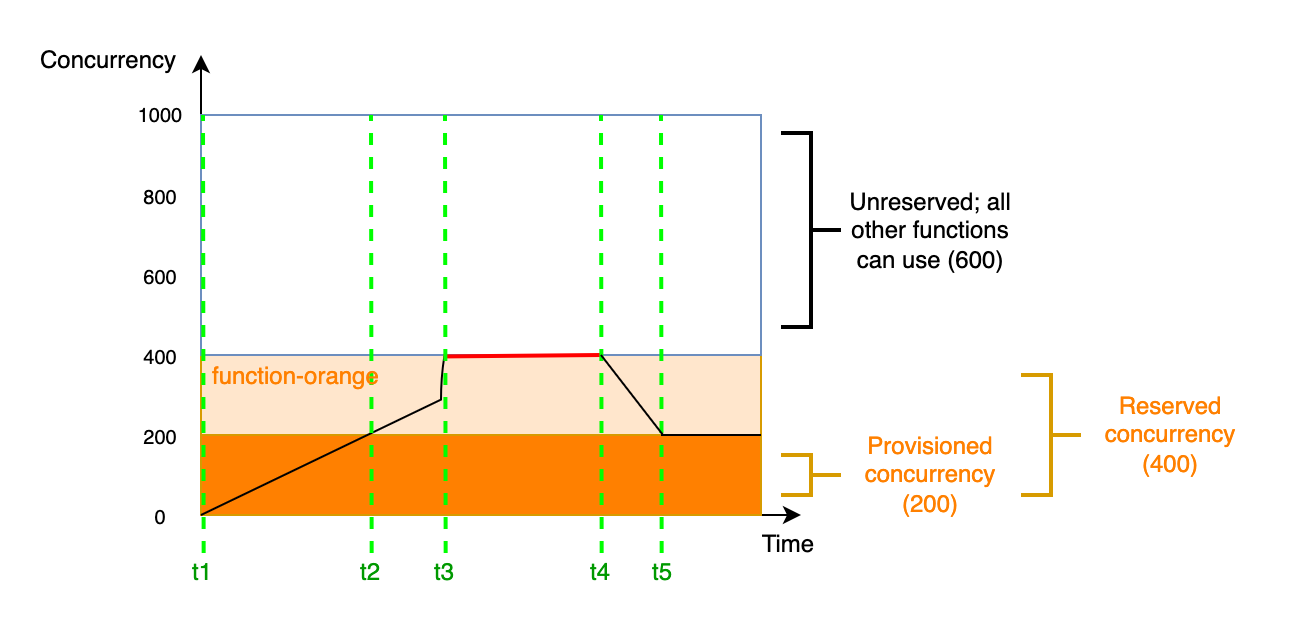
So what is the difference between reserved and unreserved concurrency?
To understand this we have to take one step back and understand how AWS works with concurrency.
When you create your AWS account, AWS gives you a default Lambda account limit concurrency (usually 10). Think of this like a pool of concurrency. This pool of concurrency is available to every function in your AWS account.
Every Lambda function you create by default has unreserved concurrency and can use any amount of concurrency they need. They can use 1 or 10 concurrency units, depending on how many they need.
When a function uses unreserved concurrency it can use up as much as it needs from the pool of total concurrency and starve other functions.
Reserved concurrency on the other hand guarantees your function always has a set number of concurrency.
For example if you raise your account concurrency limit to 100, and give 20 reserved concurrency units to one function, then the other functions that have unreserved concurrency can at most take up 80 concurrency units in total.
This is especially useful for functions that are mission-critical and cannot afford to be throttled.
Furthermore, if you know how much concurrent invocations a certain function needs at scale, you can set that number and ensure it always has enough concurrency for its workload.
Demo Example
Let’s see how we can easily configure the concurrency settings for a given Lambda function.
Head into your AWS console and select the Lambda service.
Create or select an existing function. Below you will see the Configuration tab.
On the left hand sidebar you will see the concurrency and recursion detection link.

Next click on the edit button in the first section “concurrency”:
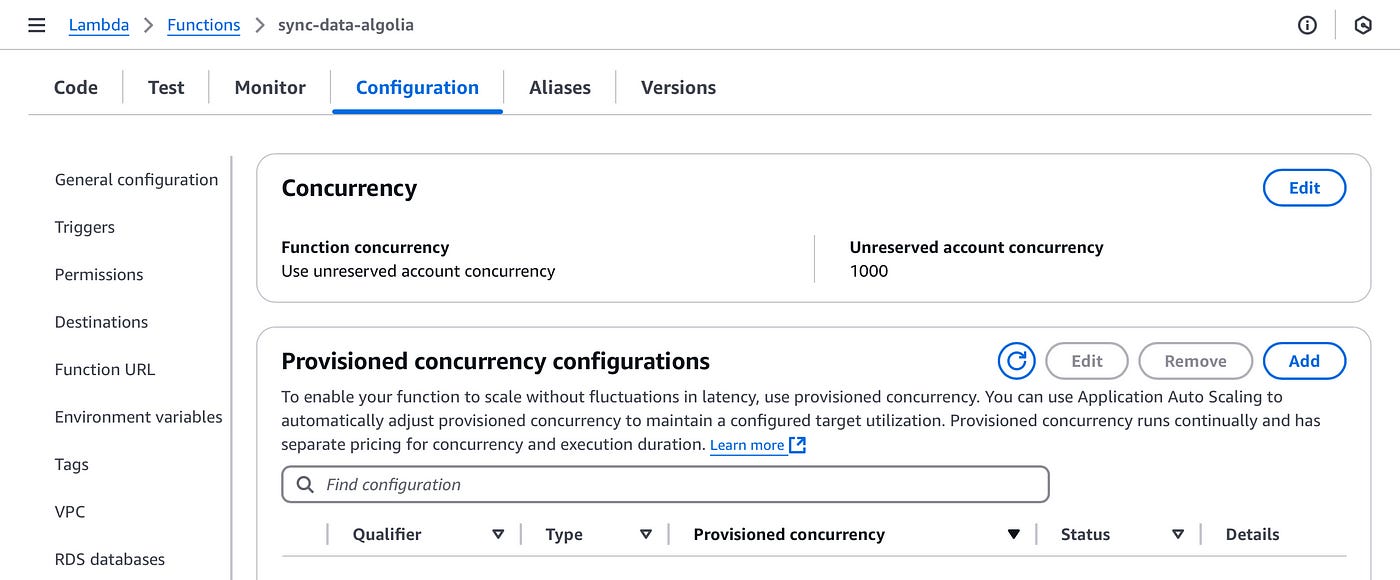
As you can see my AWS account has a total concurrency limit of 1000.
On this next page you can configure the number of concurrency for that function.
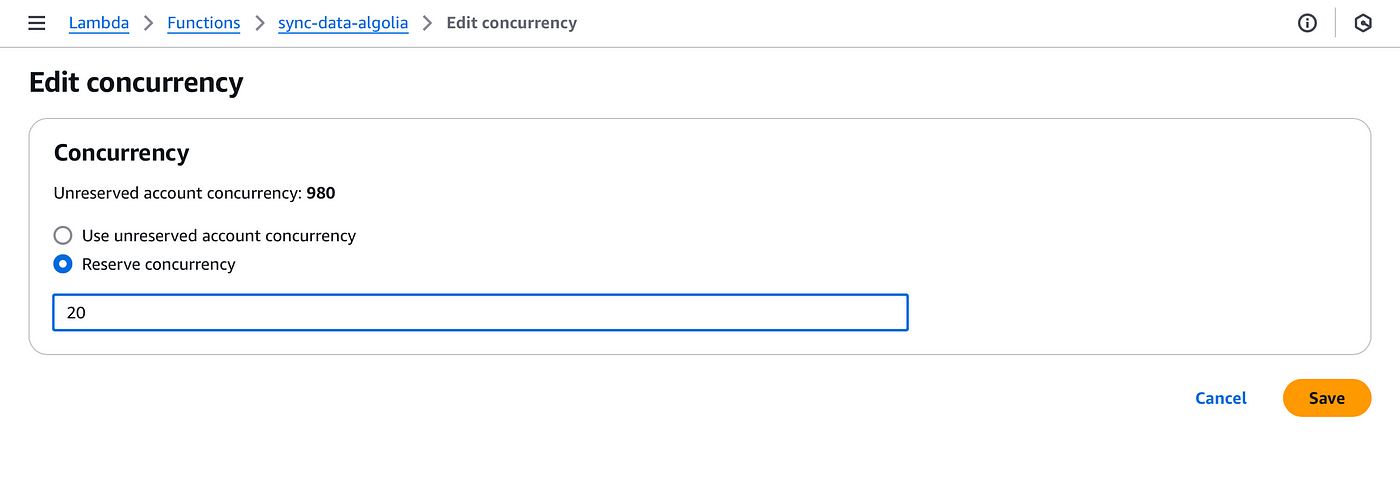
Here I’ve set 20 concurrency units for this function. Now this function will guarantee to always have 20 simultaenous invocations at any time.
You can click on save to apply the configurations.
Best Practices
Here are some general rules of thumb to follow when provisioning reserved or unreserved concurrency:
For functions that may not be invoked often, you can leave them on unreserved concurrency.
If you don’t want to limit a function to a given number of concurrency, to allow it to scale as much as it needs, you can leave it with unreserved concurrency. Just make sure the functions that need a minimum concurrency have reserved concurrency.
Finally, a function that either you want to limit its concurrency or guarantee a minimum concurrency, should be set to reserved concurrency.
You should note that reserved concurrency also limits the total number of simulatenous invocations for that function at any time. So while it guarantees concurrency, it also limits it at the same time.
👋 My name is Uriel Bitton and I’m committed to helping you master Serverless, Cloud Computing, and AWS.
🚀 If you want to learn how to build serverless, scalable, and resilient applications, you can also follow me on Linkedin for valuable daily posts.
Thanks for reading and see you in the next one!